Анализ и фильтрация TCP/IP пакетов
В одном из докладов Министерства Обороны США, выполненном по запросу Конгресса, отмечалось, что в последнее время число атак на компьютеры вооруженных сил увеличилось. При этом атакующие, главным образом, используют программы захвата и анализа трафика TCP/IP, который передается по сети Internet. Надо сказать, что проблема эта не новая. Еще во время начала проекта Athena в Масачусетском Технологическом Институте, в результате которой появилась система Керберос, одной из основных целей проекта называлась защита от захвата и анализа пакетов.
До последнего времени, в российском секторе Internet хотя и знали, что такая проблема существует, хотя провайдеры и пользовались сами сканированием, серьезных шагов по защите от этого сканирования не предпринимали. В данном случае речь идет о том, что требование тотальной защиты, как это имеет место во всех зарубежных коммерческих и правительственных сетях, не выдвигалось. Не смотря на то, что Relcom первым продемонстрировал в 1991 году возможности бесконтрольного, со стороны государства, распространения информации через Internet, ни Demos, ни AO Relcom не ставили перед собой задачи сплошной защиты своих внутренних сетей от атаки из вне при помощи просмотра содержания IP-пакетов.
Надо сказать, что довольно долгое время такая практика себя оправдывала. Серьезных нарушений в работе сети не происходило, а атаки на шлюзы и локальные подсети успешно отбивались системами фильтрации трафика. Но к осени 1996 года ситуация изменилась. И главной причиной изменения стало внедрение системы доступа к сети по dial-ip. Теперь в сети появилось большое количество случайных людей со стороны. Кроме того, внедрение Internet во многих московских вузах привело к увеличению среди пользователей сети доли студентов. При этом следует отметить, что доступ из академических и учебных заведений в Internet по большей части остается бесплатным для пользователей, а это значит, что ресурсами сети можно пользоваться круглосуточно, не заботясь о том, сколько у тебя в кармане денег.
Склонность человеческой натуры к подсматриванию и подглядыванию хорошо известна. А если за это еще и не накажут, и заниматься этим можно сколько душе угодно, то вероятность появления любопытных резко возрастает.
К осени 1996 года число зарегистрированных пользователей Dial-IP составило несколько тысяч человек только в AO Relcom. SovamTeleport начал заниматься предоставлением такого доступа на полгода раньше (с осени 1995), следовательно там число пользователей должно быть еще больше. Кроме того, многие университеты, учебные заведения и научно-исследовательские организации для своих сотрудников создали модемные пулы. Естественно, что администраторы подсетей или их близкие друзья также не могли пройти мимо возможности работать на дому. Исходя из этого, можно предположить, что только в Москве число пользователей Dial-IP составляет несколько десятков тысяч человек.
Совершенно очевидно, что среди такого количества людей обязательно найдется некто, кто посвятит все свое свободное время исследованию сети, тем более что слава всемогущих хакеров, взламывающих компьютеры Пентагона, не дает спать спокойно многим.
И вот в середине сентября 1996 года прозвенел первый звоночек. Точнее, на эту проблему обратил внимание наших провайдеров CERT (Computer Emagency Response Team). В Канаде были зарегистрированы попытки входа в систему по различным портам TCP с указанием действительно существовавших идентификаторов и паролей пользователей. Попытку зарегистрировала программа межсетевого фильтра (FilreWall), о чем и сообщила администратору. Администратор оказался человеком дотошным и стал выяснять кто и откуда пытался проникнуть в систему.
Двухнедельные занятия по изучению файлов отчетов о доступе к основным компьютерам центров управления российскими сетями показали удручающую картину. Действительно, на многих машинах наблюдались посещения в режиме привилегированных пользователей с адресов, которые не ассоциировались ни с одним из тех лиц, кому такой доступ был разрешен. Были найдены и списки идентификаторов и паролей, и инструмент, которым пользовались взломщики, и отчеты этой программы, которые хранились злоумышленниками на компьютерах за пределами российской части Internet.
Собственно определить кто и откуда коллекционировал информацию не представляло большого труда, но главным был вопрос о том, что в этом случае следует предпринимать. Ведь подобного прециндента в практике российского Internet-сообщества еще не было.
Во-первых, конечно надо было защищаться. Средства защиты хорошо известны - это фильтрация трафика и шифрация обменов. Благо на настоящий момент Гос.тех комиссией выдано более сотни лицензий на возможность проведения такого сорта мероприятий и сертифицировано как аппаратное, так и программное обеспечение. Но пассивная оборона - это только половина дела, хотелось еще и наказать наглецов. А вот с последним и возникли проблемы. В принципе, по новому российскому законодательству предусмотрены наказания вплоть до лишения свободы на строк до семи лет за компьютерные преступления, но для этого надо вести следственные мероприятия, передавать дело в суд и т.п. Все это не входит в компетенцию провайдеров, потому что может занять много времени, а кроме того о таких прецидентах, что-то пока ничего слышно не было.
Общение с организацией, предоставившей Dial-IP вход, также не дало гарантий от повторения подобных инцидентов. Поэтому было принято решение зафильтровать сетки, с которых осуществлялся первоначальный вход в сеть при взломе.
К чему привела эта практика, на своей шкуре почувствовали многие пользователи сети. На первый взгляд, вроде ничего страшного, ну не пускают тебя к отечественным информационным ресурсам, а мы, что называется, и не хотели. Будем ходить на Запад. Но не тут-то было.
Дело в том, что к отечественным информационным сервисам относится и служба DNS. DNS обслуживает запросы на получение по доменному имени машины ее IP-адреса. Каждый домен имеет несколько серверов, которые могут удовлетворить запрос пользователя, но только один из них является главным. Все остальные время от времени сверяют информацию в своей базе данных с информацией в базе данных главного сервера. При фильтрации обычно закрывают порты TCP. Это значит, что отвечать на запросы, которые используют 53 порт UDP, сервер будет, а вот осуществить копирование описания зоны на дублирующий сервер, которое производится по 53 порту TCP, межсетевой фильтр не даст. Как результат, дублирующие сервера будут отказывать в обслуживании, и доступ к ресурсам, из-за невозможности получить за приемлемое время IP-адрес, будет затруднен.
В результате доступ к такому информационному ресурсу, как World Wide Web, происходит через "пень-колоду". Что говорить о доступе к отечественным ресурсам. Ведь не "видно" не только тех, кто спрятался за "стенами", но и тех, кто разместил там серверы DNS. Особенно пикантной становится ситуация, если в защищенную зону попадет root-сервер DNS для доменов SU и RU.
Сколько теперь будет успокаиваться поднятая этими действиями волна - не известно, но то, что провайдеры, к которым в данном случае относятся и некоммерческие сети, должны вместе договориться об общих принципах политики безопасности - это очевидно, в противном случае ситуация будет повторяться постоянно, но уже гораздо с большими последствиями для всех заинтересованных сторон.
И попутно, хотелось бы заметить, что всякие разговоры о проблемах с сервером InfoArt, когда, как утверждалось, было подменено содержание базы данных службы доменных имен, могут являться следствием указанных выше причин. Хотя то, что события совпали по времени может быть простой случайностью.
После столь долгого вступления хотелось все же обратиться к тому средству, которым воспользовались злоумышленники. Программы, позволяющие захватывать пакеты из сети называются sniffers (буквально - "нюхачи", но мне кажется лучше назвать их "пылесосами", т.к. сосут они все подряд, хотя есть и интеллектуальные, которые из всех пакетов выбирают только то, что нужно).
Первые такие программы использовали то, что в сетях Ethernet все компьютеры подсоединяются на один кабель. В обычном режиме карта Ethernet принимает только те фреймы, которые ей предназначены, т.е. указаны в заголовке фрейма. Однако в целях отладки многие карты можно заставить работать в режиме "пылесоса", тогда они будут принимать все фреймы, которые передаются по кабелю. Такой режим работы карты называется promiscuous mode. Если можно получить пакет в машину, то, следовательно, его можно проанализировать.
Главная проблема, связанная с "нюхачами" заключается в том, чтобы они успевали перерабатывать весь трафик, который проходит через интерфейс. Код одной из достаточно эффективных программ этого типа (Esniff) был опубликован в журнале Phrack. Esniff предназначена для работы в Sunos. Программа очень компактная и захватывает только первые 300 байтов заголовка, что вполне достаточно для получения идентификатора и пароля telnet-сессии. Программа свободно распространяется по сети и каждый желающий может ее "срисовать" по адресу ftp://coombs.anu.edu.au/pub/net/log. Существуют и другие программы этого типа и не только для платформ Sun. Это Gobler, athdump, ethload для MS-DOS или Paketman, Interman, Etherman, Loadman - для целого ряда платформ, которые включают в себя Alpha, Dec-Mips, SGI и др. "Нюхачи" существуют не только для Ethernet. Многие компании выпускают системы анализа трафика и для высокоскоростных линий передачи данных. Достаточно зайти на домашнюю страницу AltaVista и запустить запрос, состоящий из одного слова "sniffer" как вы сразу получите целый список страниц на данную тему. Лучше правда "sniffer AND security", т.к. система может понять вас буквально и выложить информацию и об органах дыхания.
Когда программы анализа трафика писались, то предполагалось, что пользоваться ими будут профессионалы, отвечающие за надежность работы сети. Однако, как это часто бывает, система оказалась обоюдоострой. Как же бороться с непрошенными гостями?
Во-первых, если система многопользовательская, то при помощи команды ifconfig можно увидеть интерфейс, который работает в режиме "пылесоса". Среди флагов появляется значение PROMISC. Однако, злоумышленник может подменить команду ifconfig, чтобы она не показывала этот режим работы. Поэтому следует убедиться в том, что программа та, которая была первоначально, а во-вторых, ее протестировать.
Обнаружить "пылесос" на других машинах сети нельзя, особенно это касается машин с MS-DOS. Поэтому от сканирования защищаются путем установки межсетевых фильтров и введения механизмов шифрации либо всего трафика, либо только идентификаторов и паролей.
Существуют и аппаратные способы защиты. Ряд сетевых адаптеров не поддерживает режим promiscuous mode. Если эти карты использовать для организации локальной сети, то можно обезопасить себя от "подглядывания".
Для того, чтобы "подглядывать" вовсе не обязательно включать режим принятия всех пакетов. Если запустить программу анализа пакетов на шлюзе, то вся информация также будет доступна, т.к. шлюз пропускает через себя все пакеты в/из локальной сети, для которой он является шлюзом.
В заключении хотелось бы сказать, вслед за Jeff Schiller и Joanne Costell из Масачусетского Технологического Института, что, для использования sniffer не надо иметь семи пядей во лбу, не надо иметь диплом о высшем образовании и вообще запустить программу и воспользоваться результатами может и младенец. То, что кто-то смог наколлекционировать чужие пароли и идентификаторы не говорит о его уме или профессиональной пригодности. Единственным последствием таких действий станет неминуемое ужесточение правил использования сети, от которого плохо станет всем.
BGP
- это другой протокол внешней маршрутизации, который появился позже EGP. В своих сообщениях он уже позволяет указать различные веса для маршрутов, и, таким образом, способствовать выбору наилучшего маршрута. Однако, назначение этих весов не определяется какими-то независимыми факторами типа времени доступа к ресурсу или числом шлюзов на пути к ресурсу. Предпочтения устанавливаются администратором и потому иногда такую маршрутизацию называют политической маршрутизацией, подразумевая, что она отражает техническую политику администрации данной автономной системы при доступе из других автономных систем к ее информационным ресурсам. Протокол BGP используют практически все российские крупные IP-провайдеры, например крупные узлы сети Relcom.
К внутренним протоколам относятся протоколы Routing Information Protocol (RIP), HELLO, Intermediate System to Intermediate System (ISIS), Shortest Path First (SPF) и Open Shortest Path First (OSPF).
Протокол RIP (Routing Information Protocol) предназначен для автоматического обновления таблицы маршрутов. При этом используется информация о состоянии сети, которая рассылается маршрутизаторами (routers). В соответствии с протоколом RIP любая машина может быть маршрутизатором. При этом, все маршрутизаторы делятся на активные и пассивные. Активные маршрутизаторы сообщают о маршрутах, которые они поддерживают в сети. Пассивные маршрутизаторы читают эти широковещательные сообщения и исправляют свои таблицы маршрутов, но сами при этом информации в сеть не предоставляют. Обычно в качестве активных маршрутизаторов выступают шлюзы, а в качестве пассивных - обычные машины (hosts).
В основу алгоритма маршрутизации по протоколу RIP положена простая идея: чем больше шлюзов надо пройти пакету, тем больше времени требуется для прохождения маршрута. При обмене сообщениями маршрутизаторы сообщают в сеть IP-номер сети и число "прыжков" (hops), которое надо совершить, пользуясь данным маршрутом. Надо сразу заметить, что такой алгоритм справедлив только для сетей, которые имеют одинаковую скорость передачи по любому сегменту сети. Часто в реальной жизни оказывается, что гораздо выгоднее воспользоваться оптоволокном с 3-мя шлюзами, чем одним медленным коммутируемым телефонным каналом.
Другая идея, которая призвана решить проблемы RIP, - это учет не числа hop'ов, а учет времени отклика. На этом принципе построен, например, протокол OSPF. Кроме этого OSPF реализует еще и идею лавинной маршрутизации. В RIP каждый маршрутизатор обменивается информацией только с соседями. В результате, информации о потере маршрута в сети, отстоящей на несколько hop'ов от локальной сети, будет получена с опозданием. Лавинная маршрутизация позволяет решить эту проблему за счет оповещения всех известных шлюзов об изменениях локального участка сети.
К сожалению, многовариантную маршрутизацию поддерживает не очень много систем. Различные клоны Unix и NT, главным образом ориентированы на протокол RIP. Достаточно посмотреть на программное обеспечение динамической маршрутизации, чтобы убедится в этом. Программа routed поддерживает только RIP, программа gated поддерживает RIP, HELLO, OSPF, EGP и BGP, в Windows NT поддерживается только RIP.
Поэтому мы рассмотрим возможность динамического управления таблицей маршрутов только по протоколу RIP.
Checking remote host
- в этом случае используется так называемое ICMP Echo Message. Если необходимо проверить наличие стека TCP/IP на удаленной машине, то на нее посылается сообщение этого типа. Как только система получит это сообщение, она немедленно подтвердит его получение.
Последняя возможность широко используется в Internet. На ее основе работает команда ping.
Ix: {2} ping apollo.polyn.kiae.su PING apollo.polyn.kiae.su (144.206.160.40): 56 data bytes 64 bytes from 144.206.160.40: icmp_seq=0 ttl=255 time=1.401 ms 64 bytes from 144.206.160.40: icmp_seq=1 ttl=255 time=0.844 ms 64 bytes from 144.206.160.40: icmp_seq=2 ttl=255 time=0.807 ms 64 bytes from 144.206.160.40: icmp_seq=3 ttl=255 time=0.912 ms 64 bytes from 144.206.160.40: icmp_seq=4 ttl=255 time=0.797 ms 64 bytes from 144.206.160.40: icmp_seq=5 ttl=255 ti^C --- apollo.polyn.kiae.su ping statistics --- 6 packets transmitted, 6 packets received, 0% packet loss round-trip min/avg/max = 0.797/0.930/1.401 ms Ix: {3}
В приведенном выше примере сообщения посылаются на машину apollo.polyn.kiae.su, которая подтверждает их получение.
Другое использование ICMP - это получение сообщения о "кончине" пакета на шлюзе. При этом используется время жизни пакета, которое определяет число шлюзов, через которые пакет может пройти. Программа, которая использует этот прием, называется traceroute. К более подробному обсуждению ее возможностей мы вернемся в разделе 2.5. Здесь же только укажем, что она использует сообщение TIME EXECEED протокола ICMP.
quest:/usr/paul:\[1\]%traceroute www.netscape.com traceroute to www3.netscape.com (205.218.156.44), 30 hops max, 40 byte packets 1 Moscow-KIAE-4.Relcom.EU.net (144.206.136.12) 7 ms 4 ms 4 ms 2 Moscow-KIAE-3.Relcom.EU.net (193.125.152.14) 5 ms 4 ms 4 ms 3 Moscow-M9-2.Relcom.EU.net (193.124.254.37) 10 ms 8 ms 10 ms 4 StPetersburg-LE-1.Relcom.EU.net (193.124.254.33) 53 ms 24 ms 29 ms 5 Helsinki2.FI.EU.net (134.222.4.1) 33 ms 31 ms 39 ms 6 Pennsauken1.NJ.US.EU.net (134.222.228.30) 159 ms 292 ms 125 ms 7 mcinet-2.sprintnap.net (192.157.69.48) 528 ms 419 ms 400 ms 8 core2-hssi2-0.WestOrange.mci.net (204.70.1.49) 411 ms 495 ms 397 ms 9 borderx1-fddi-1.SanFrancisco.mci.net (204.70.158.52) 387 ms 342 ms 231 ms 10 borderx1-fddi-1.SanFrancisco.mci.net (204.70.158.52) 264 ms 265 ms 261 ms 11 netscape.SanFrancisco.mci.net (204.70.158.110) 250 ms 262 ms 252 ms 12 205.218.156.44 (205.218.156.44) 279 ms 295 ms 299 ms quest:/usr/paul:\[2\]%
При посылке пакета через Internet traceroute устанавливает значение TTL (Time To Live) последовательно от 1 до 30 (значение по умолчанию). TTL определяет число шлюзов, через которые может пройти IP-пакет. Если это число превышено, то шлюз, на котором происходит обнуление TTL, высылает ICMP-пакет. Traceroute сначала устанавливает значение TTL равное единице - отвечает ближайший шлюз, затем значение TTL равно 2 - отвечает следующий шлюз и т. д. Если пакет достиг получателя, то в этом случае возвращается сообщение другого типа -
Delete
. Например, если нам надо изменить значение шлюза по умолчанию, то мы можем выполнить следующую последовательность команд:
/usr/paul>route delete default /usr/paul/route add default 144.206.136.10 netmask 255.255.224.0
В данном случае сначала мы удалим из таблицы (пример 2.1) маршрут умолчания, а затем добавим туда новый. При удалении маршрута достаточно назвать только адрес назначения, чтобы route идентифицировала маршрут, который следует удалить.
Можно по команде route получить информацию и о конкретном маршруте, но удобнее все-таки пользоваться командой netstat. В последней и информации указывается больше, и можно получить такую информацию, о которой вы просто можете даже не подозревать, если приходят ICMP-сообщения или используется динамическая маршрутизация.
В заключении обсуждения вопросов статической маршрутизации хотелось бы сделать небольшое замечание по поводу Windows NT. До версии 4.0 в Windows NT штатно существовала только статическая маршрутизация. Для сетей локальных с надежными линиями связи этого вполне достаточно. Фактически, администратору нужно только указать IP-адреса на каждом из сетевых интерфесов, указать адрес шлюза по умолчанию и поднять флажок пересылки пакетов с одного интерфейса на другой. После этого все должно работать. Если локальная сеть подключается к провайдеру, то, как правило, все сводится к получению адреса из сети провайдера для внешнего интерфейса, т.е. интерфейса, который будет связывать вас с адресом шлюза провайдера и адресом своей сети или подсети. Если только провайдер не затеет изменения структуры своей сети, вес будет работать годами без каких-либо изменений. Для таких сетей шлюз на основе Windows NT можно организовать. Однако, не все так просто, когда речь идет о сети или подсети, которые подключаются в качестве части сети, которая не организована по иерархическому принципу. В этом случае возможно изменение наилучших маршрутов гораздо чаще, чем один раз в десятилетие и в этом случае статическая маршрутизация может оказаться недостаточной. Кроме того, важным фактором повышения надежности сетевого взаимодействия является наличие нескольких маршрутов к одним и тем же информационным ресурсам. В случае отказа одного из них можно использовать другие. Но проблема заключается в том, что система всегда использует тот маршрут, который первым встретился в таблице маршрутов, хотя и существуют мультимаршрутные системы, но они распространены, мягко говоря не очень широко. Следовательно, маршруты из таблицы надо удалять и вносить. Если сеть работает не устойчиво, то это превращается в головную боль администратора. Вот почему до версии Windows NT 4.0 рассматривать эту систему в качестве реального претендента на маршрутизатор не представляется возможным. В Windows NT 4.0 появилась поддержка динамической маршрутизации в лице протокола RIP, но поддержки других протоколов маршрутизации пока еще нет.
Таким образом, мы подошли к проблеме автоматического управления таблицей маршрутов на основе информации, получаемой из сети. Такая процедура называется динамической маршрутизацией.
Detecting unreachаble destination
- если пакет не может достичь места назначения, то шлюз, который не может доставить пакет, сообщает об этом отправителю пакета. Информировать о невозможности доставки сообщения может и машина, чей IP-адрес указан в пакете. Только в этом случае речь будет идти о портах TCP и UDP, о чем будет сказано чуть позже.
, т.к. IP-пакет передается на транспортный уровень, а на нем нет обслуживания запросов traceroute (см. раздел 2.5).
После протоколов межсетевого уровня перейдем к протоколам транспортного уровня и первым из них рассмотрим протокол UDP.
Динамическая маршрутизация
Прежде чем вникать в подробности и особенности динамической маршрутизации обратим внимание на двухуровневую модель, в рамках которой рассматривается все множество машин Internet. В рамках этой модели весь Internet рассматривают как множество автономных систем (autonomous system - AS). Автономная система - это множество компьютеров, которые образуют довольно плотное сообщество, где существует множество маршрутов между двумя компьютерами, принадлежащими этому сообществу. В рамках этого сообщества можно говорить об оптимизации маршрутов с целью достижения максимальной скорости передачи информации. В противоположность этому плотному конгломерату, автономные системы связаны между собой не так тесно как компьютеры внутри автономной системы. При этом и выбор маршрута из одной автономной системы может основываться не на скорости обмена информацией, а надежности, безотказности и т.п.
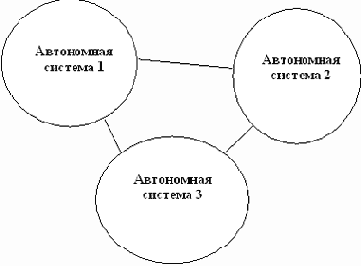
Рис. 2.24. Схема взаимодействия автономных систем
Сама идеология автономных систем возникла в тот период, когда ARPANET представляла иерархическую систему. В то время было ядро системы, к которому подключались внешние автономные системы. Информация из одной автономной системы в другую могла попасть только через маршрутизаторы ядра. Такая структура до сих пор сохраняется в MILNET.
На рисунке 2.24 автономные системы связаны только одной линией связи, что больше соответствует тому, как российский сектор подключен к Internet. В классических публикациях по Internet взаимодействие автономных частей чаще обозначают пересекающимися кругами, подчеркивая тот факт, что маршрутов из одной автономной системы в другую может быть несколько.
Обсуждение этой модели Internet необходимо только для того, чтобы объяснить наличие двух типов протоколов динамической маршрутизации: внешних и внутренних.
EGP
предназначен для анонсирования сетей, которые доступны для автономных систем за пределами данной автономной системы. По данному протоколу шлюз одной AS передает шлюзу другой AS информацию о сетях из которых состоит его AS. EGP не используется для оптимизации маршрутов. Считается, что этим должны заниматься протоколы внутренней маршрутизации.
/Etc/protocols
или прочитать в RFC Assigned Numbers.
Содержание файла /etc/protocols:
Ix: {3} more protocols # # Internet (IP) protocols # # $Id: protocols,v 1.2.8.1 1995/08/30 06:19:30 davidg Exp $ # from: @(#)protocols 5.1 (Berkeley) 4/17/89 # # Updated for FreeBSD based on RFC 1340, Assigned Numbers (July 1992). # ip 0 IP # internet protocol, pseudo protocol number icmp 1 ICMP # internet control message protocol igmp 2 IGMP # Internet Group Management ggp 3 GGP # gateway-gateway protocol ipencap 4 IP-ENCAP # IP encapsulated in IP (officially ``IP'') st 5 ST # ST datagram mode tcp 6 TCP # transmission control protocol egp 8 EGP # exterior gateway protocol pup 12 PUP # PARC universal packet protocol udp 17 UDP # user datagram protocol hmp 20 HMP # host monitoring protocol xns-idp 22 XNS-IDP # Xerox NS IDP rdp 27 RDP # "reliable datagram" protocol iso-tp4 29 ISO-TP4 # ISO Transport Protocol class 4 xtp 36 XTP # Xpress Tranfer Protocol idpr-cmtp 39 IDPR-CMTP # IDPR Control Message Transport rsvp 46 RSVP # Resource ReSerVation Protocol vmtp 81 VMTP # Versatile Message Transport ospf 89 OSPFIGP # Open Shortest Path First IGP ipip 94 IPIP # Yet Another IP encapsulation encap 98 ENCAP # Yet Another IP encapsulation
Как видно из содержания файла protocols, практически всем основным протоколам присвоены номера. Другой группой магических цифр являются номера портов, которые закреплены за информационными сервисами Internet.
Информационный сервис - это прикладная программа, которая осуществляет обслуживание на определенном порте TCP или UDP. Собственно WKS - это и есть совокупность этих сервисов Internet. К сервисам относятся: доступ в режиме удаленного терминала, доступ к файловым архивам FTP, доступ к серверам World Wide Web и т. п. Распределение сервисов по портам можно найти в файле
/Etc/services
. Сам файл сервисов очень большой, поэтому приведем только небольшой его фрагмент с наиболее интересными и популярными сервисами.
Фрагмент содержания файла /etc/services:
quest:/etc:\[2\]>cat services tcpmux 1/tcp # TCP port service multiplexer echo 7/tcp echo 7/udp ... ftp 21/tcp # 22 - unassigned telnet 23/tcp # 24 - private smtp 25/tcp mail # 26 - unassigned time 37/tcp timserver time 37/udp timserver rlp 39/udp resource # resource location whois 43/tcp nicname domain 53/tcp nameserver # name-domain server domain 53/udp nameserver bootps 67/tcp # BOOTP server bootps 67/udp bootpc 68/tcp # BOOTP client bootpc 68/udp tftp 69/udp gopher 70/tcp # Internet Gopher gopher 70/udp finger 79/tcp www 80/tcp http # WorldWideWeb HTTP www 80/udp # HyperText Transfer Protocol
Среди сервисов, определенных в этом фрагменте, есть не только информационные сервисы типа World Wide Web или Gopher, но и протокол маршрутизации RIP, и протокол удаленной загрузки bootp, и сервис доменных имен BIND, и другие протоколы, которые нацелены на повышение работы сети и чрезвычайно полезны при администрировании сети.
При работе через стек протоколов TCP/IP сообщения, которыми обмениваются приложения, сначала инкапсулируются в сегменты TCP или дейтаграммы UDP, при этом указывается соответствующий порт транспортного протокола. Потом транспортные протоколы мультиплексируются в IP, который запоминает номер протокола. Все IP-пакеты передаются по сети получателю, где происходит обратная операция изъятия информации из оболочки TCP/IP. Сначала по номеру протокола в модуле IP выделенные данные пересылаются соответствующему протоколу транспортного уровня. На транспортном уровне по номеру порта получателя определяется какому сервису данные посланы. Все это графически изображено на рисунке 2.19.

Рис. 2.19. Использование номеров портов и номеров протоколов для передачи данных
Однако, этим механизм взаимодействия приложений в рамках TCP/IP не исчерпывается. Дело в том, что кроме статически назначенных WKS существуют еще динамически назначаемые сервисы.
Динамически назначаемые номера портов TCP и UDP используются для того, чтобы можно было организовать обслуживание множества запросов по сети к одному WKS. В том же примере стрелочки только в одном направлении указаны не случайно. К серверу протокола HTTP могут обращаться сразу несколько клиентов, следовательно должен быть механизм, который бы позволил распараллелить их обслуживание. Таким механизмом служит динамическое назначение портов (рисунок 2.20). Происходит это назначение в момент установки соединения. Клиент, запрашивая обслуживание, обращается к сервису по номеру порта WKS, но при этом сообщает, что принимать ответы он будет по номеру порта, отличному от WKS. Таким образом, сервер может обслуживать запросы к одному и тому же порту WKS, используя разные порты при ответе. Образующаяся при этом пара (IP-адрес, номер порта) называется сокетом (буквально "розетка"). Таким образом, можно сказать, что http-сервер для обслуживания использует сокет, например, 144.206.130.137;80, а клиент, который к нему обращается, сокет 144.206.130.138;8080. Графически определение сокета можно продемонстрировать на примере протокола TCP.
Рис. 2.20. Динамическое назначение портов. Образование сокетов
Описывая взаимодействие в рамках TCP/IP обмена, мы до сих пор обходили стороной вопросы связанные с тем, как пакет реально транспортируется по сети. Все наши примеры ограничивались работой в рамках локальной сети. Теперь пора поговорить о том, как осуществляется передача пакетов по сети, или в терминах сетевого обмена - маршрутизация.
Flow control
- если принимающая машина (шлюз или реальный получатель информации) не успевает перерабатывать информацию, то данное сообщение приостанавливает отправку пакетов по сети.
Админисрирование сети и сервисов INTERNET
- это коллективный продукт американских университетов, который был разработан для работы сети NFSNET. Права copyright закреплены за Корнельским университетом, хотя части кода являются собственностью других университетов и ассоциаций.
Gated - это модульная программа предназначенная организации много функционального шлюза, который мог бы обслуживать как внутреннюю маршрутизацию, так и внешнюю. Gated поддерживает протоколы RIP (версии 1 и 2), HELLO, OSPF версии 2, EGP версии 2 и BGP версий от 2 до 4. Все перечисленные возможности относятся к версии 3.5. На системах типа HPUX 9.x или IRIX 6.x могут стоять и более ранние версии, которые всего этого набора протоколов могут и не поддерживать.
Рассмотрим два основных примера использования gated в локальной сети: вместо routed на обычной машине и на машине-шлюзе в другую сеть. При этом будем опираться на следующую схему, изображенную на рисунке 2.25.
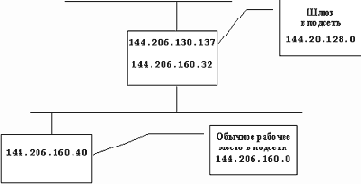
Рис. 2.25. Подключение локальной сети к Internet и настройки gated
Gated настраивается при помощи своего файла конфигурации /etc/gated.conf. Именно в нем пишутся все команды настройки, которые gated проверяет при запуске.
При работе на обычной машине, системе надо только указать интерфейс и протокол динамической маршрутизации, который gated должна использовать:
# # Interface shouldn`t be removed from routing table # interface 144.206.160.40 passive ; # # routing protocol is rip. # rip yes;
В большинстве случаев достаточно просто указать протокол, т.к. интерфейс попадет в таблицу маршрутизации после выполнения команды ifconfig.
Теперь обратимся к настройкам gated на машине-шлюзе. В принципе, можно также обойтись одним указанием на протокол RIP и все будет работать. Если же надо сохранять маршруты через интерфейсы в таблице маршрутов, то следует указать в файле конфигурации оба интерфеса:
# Interfaces shouldn`t be removed from routing table interface 144.206.160.32 passive ; interface 144.206.130.137 passive ; # routing protocol is rip. rip yes;
Однако можно использовать и более сложное описание, основанное на логике работы gated. А логика эта состоит в том , что gated объявляет соседним шлюзам по RIP, что подсеть 144.206.160.0 доступна через интерфейс 144.206.130.137, в свою очередь для подсети gated объявляет, что весь мир доступен через интерфейс 144.206.160.32. Очевидно, что это логика заимствована из архитектуры внешних протоколов маршрутизации и распространена на протоколы внутренние. Это позволяет вести описание маршрутов в едином ключе.
rip yes; export proto rip interface 144.206.130.137 { proto direct { announce 144.206.160.0 metric 0 ; } ; } ; export proto rip interface 144.206.160.32 { proto rip interface 144.206.130.137 { announce all ; } ; } ;
Первая команда export анонсирует подсеть 144.206.160.0 через интерфейс 144.206.130.137. При этом сообщается, что это шлюз в данную подсеть, т.е. интерфейс 144.206.130.137 расположен на машине, которая включена в эту подсеть. О том, что пакеты для подсети надо посылать непосредственно на этот интерфейс говорит предложение proto direct, а то, что интерфейс стоит на шлюзе в подсеть говорит метрика, равная 0.
Второе предложение сообщает всем машинам подсети через интерфейс 144.206.160.32 все маршруты, которые данный шлюз получает из подсети 144.206.128.0 через интерфейс 144.206.130.137. Фактически осуществляется сквозная пересылка всей информации во внутрь системы.
При написании управляющих предложений export следует всегда помнить, что внешнее предложение определяет всегда интерфейс, через который сообщается информация, а внутреннее предложение определяет источник, через который эту информацию получает gated.
Важным является и синтаксис предложений, который сильно смахивает на синтаксис языка программирования С.
Во всех руководствах по gated приводится еще один пример, когда сеть, через подсеть подключают к Internet. Здесь приведем пример из руководства к gated 3.5.
rip yes; export proto rip interface 136.66.12.3 metric 3 { proto rip interface 136.66.1.5 { announce all ; } ; } ; export proto ripinterface 136.66.1.5 { proto rip interface 136.66.12.3 { announce 0.0.0.0 ; } ; { ;
В данном случае все, что gated получает из локальной сети через интерфейс 136.66.1.5 транслируется в подсеть, которая связывает данную сеть с Internet, через интерфейс 136.66.12.3 (речь идет только о маршрутах, так как gated работает только с таблицей маршрутов).
Второе предложение export определяет куда следует отправлять информацию по умолчание из сети, чтобы она достигла адресата, расположенного за пределами данной локальной сети. Адрес 0.0.0.0, который соответствует любой машине за интерфейсом 136.66.12.3 анонсируется через интерфейс 136.66.1.5. для всей локальной сети.
И последние замечания о gated. Они касаются возможности управлять доступом к машинам локальной сети. Если маршрут доступа к машине или локальной подсети не экспортировать во внешний мир, то о машине или подсети никто и не узнает. Правда в этом случае нельзя использовать эти машины для доступа к внешним ресурсам также.
Handshake
(буквально "рукопожатие"). В TCP используется трехфазный hand-shake:
Источник устанавливает соединение с получателем, посылая ему пакет с флагом "синхронизации последовательности номеров" (Synchronize Sequence Numbers - SYN). Номер в последовательности определяет номер пакета в сообщении приложения. Это не обязательно должен быть 0 или единица. Но все остальные номера будут использовать его в качестве базы, что позволит собрать пакеты в правильном порядке; Получатель отвечает номером в поле подтверждения получения SYN, который соответствует установленному источником номеру. Кроме этого, в поле "номер в последовательности" может также сообщаться номер, который запрашивался источником; Источник подтверждает, что принял сегмент получателя и отправляет первую порцию данных.
Графически этот процесс представлен на рисунке 2.12.

Рис. 2.12. Установка соединения TCP
После установки соединения источник посылает данные получателю и ждет от него подтверждений о их получении, затем снова посылает данные и т.д., пока сообщение не закончится. Заканчивается сообщение, когда в поле флагов выставляется бит FIN, что означает "нет больше данных".
Потоковый характер протокола определяется тем, что SYN определяет стартовый номер для отсчета переданных байтов, а не пакетов. Это значит, что если SYN был установлен в 0, и было передано 200 байтов, то номер, установленный в следующем пакете будет равен 201, а не 2.
Понятно, что потоковый характер протокола и требование подтверждения получения данных порождают проблему скорости передачи данных. Для ее решения используется "окно" - поле - window. Идея применения window достаточно проста: передавать данные не дожидаясь подтверждения об их получения. Это значит, что источник предает некоторое количество данных равное window без ожидания подтверждения об их приеме, и после этого останавливает передачу и ждет подтверждения. Если он получит подтверждение только на часть переданных данных, то он начнет передачу новой порции с номера, следующего за подтвержденным. Графически это изображено на рисунке 2.13.
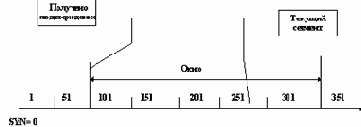
Рис. 2.13. Механизм передачи данных по TCP
В данном примере окно установлено в 250 байтов шириной. Это означает, что текущий сегмент - сегмент со смещением относительно SYN, равном 250 байтам. Однако, после передачи всего окна модуль TCP источника получил подтверждение на получение только первых 100 байтов. Следовательно, передача будет начата со 101 байта, а не с 251.
Таким образом, мы рассмотрели все основные свойства протокола TCP. Осталось только назвать наиболее известные приложения, которые использует TCP для обмена данными. Это в первую очередь TELNET и FTP, а также протокол HTTP, который является сердцем World Wide Web.
Прервем немного разговор о протоколах и обратим свое внимание на такую важнейшую компоненту всей системы TCP/IP как IP-адреса.
Ifconfig
:
/usr/paul>ifconfig ed0 inet 144.206.130.138 netmask 255.255.224.0
В данном случае интерфесу ed0 назначается адрес 144.206.130.138, при этом на сети установлена маска 255.255.224.0. В общем случае команда ifconfig имеет следующий формат:
ifconfig interface address_family [address [dest_address]] [parameters]
В этой команде параметры означают следующее:
interface - имя сетевого интерфейса;
address_famaly - тип адреса. В нашем случае - это inet, т.е. адрес Internet. Данное значение задается по умолчанию;
address - IP-адрес источника. Обычно в этом поле указывают IP-адрес который назначается сетевому интерфейсу. Если речь идет об интерфейсе Ethernet то этого адреса достаточно для его настройки.
dest_address - IP-адрес получателя. Данный адрес указывается для интерфейсов типа "точка-точка", например, для SLIP (sl0) или PPP (ppp0). В таких соединениях к концам линии связи подключены только два интерфейса и надо задать адрес обоих. В предыдущем поле (address) задают адрес своего интерфейса, а в данном поле интерфейса, установленного на другом конце линии.
В качестве параметров можно указать маску сети, как это сделано в примере. Этот параметр - обязательный. Существуют и другие параметры, например адрес широковещания, но их используют редко и обычно в данном случае их значения назначаются по умолчанию, так, например, адрес широковещания по умолчанию ограничен локальной сетью, и это правильно, т.к. нет нужды "светиться" за пределами своего шлюза.
Команда ifconfig может быть использована и для получения информации об интерфейсе. Для этого в ней надо указать только имя:
quest:/usr/src/sys/i386/conf:\[14\]>ifconfig ed1 ed1: flags=863<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX> inet 144.206.130.138 netmask ffffe000 broadcast 144.206.159.255 quest:/usr/src/sys/i386/conf:\[15\]>
В данном случае была запрошена информация об интерфейсе ed1. Из отчета видно, какие флаги установлены для данного интерфейса и какой адрес ему назначен. С точки зрения администратора важно, что этот интерфейс в данный момент работоспособен (флаг UP) и не используется для сканирования пакетов в сети. Сканированию пакетов мы уделим достаточно внимания в разделе, посвященном вопросам безопасности сети.
Однако более исчерпывающую статистику можно получить при помощи команды netstat:
quest:/usr/src/sys/i386/conf:\[19\]>netstat - ain Name Mtu Network Address Ipkts Ierrs Opkts Oerrs Coll ed0 1500 <Link>0.0.1b.12.32.46 52848 0 45380 0 0 ed0 1500 144.206.192 144.206.192.1 52848 0 45380 0 0 ed1 1500 <Link>0.0.1b.12.32.32 659682 2354 45708 276 4423 ed1 1500 144.206.128 144.206.130.138 659682 2354 45708 276 4423 lo0 65535 <Link> 138 0 138 0 0 lo0 65535 127 127.0.0.1 138 0 138 0 0 sl0* 296 <Link> 0 0 0 0 0 sl1* 296 <Link> 0 0 0 0
В данном отчете перечислены все сетевые интерфейсы, минимальные размеры фреймов, которые могут передаваться через них, сети и IP-адреса данного хоста на этих сетях, сколько пакетов через интерфейс было принято, сколько из них было поврежденных, сколько пакетов было отправлено и сколько из них было поврежденных и, в заключении, число коллизий, зарегистрированное интерфейсом. Кроме того, в данном отчете указаны еще и Ethernet-адреса интерфейсов.
Кроме этого, следует обратить внимание интерфейс lo0, который закреплен за петлей 127.0.0.1. Для этого интерфейса также нужна команда ifconfig. /usr/paul> ifconfig lo0 inet localhost
В данном случае имя localhost будет заменено на 127.0.01.
Но Ethernet - это только один из интерфейсов, которые могут быть использованы при подключении к сети. Кроме него довольно популярны интерфейсы подключения через последовательные порты.
IPing - новое поколение протоколов IP
До сих пор, при обсуждении IP-технологии, основное внимание уделялось проблемам межсетевого обмена и путям их решения в рамках существующей технологии. Однако, все эти задачи, вызванные необходимостью приспособления IP к новым физическим средам передачи данных меркнут перед действительно серьезной проблемой - ростом числа пользователей Сети. Казалось бы, что тут страшного? Число пользователей увеличивается, следовательно растет популярность сети. Такое положение дел должно только радовать. Но проблема заключается в том, что Internet стал слишком большой, он перерос заложенные в него возможности. К 1994 году ISOC опубликовало данные, из которых стало ясно, что номера сетей класса B практически все уже выбраны, а остались только сети класса A и класса C. Класс A - это слишком большие сети. Реальные пользователи сети, такие как университеты или предприятия, не используют сети этого класса. Класс С хорош для очень небольших организаций. При современной насыщенности вычислительной техникой только мелкие конторы будут удовлетворены возможностями этого класса. Но если дело пойдет и дальше такими темпами, то класс C тоже быстро иссякнет. Самое парадоксальное заключается в том, что реально не все адреса, из выделенных пользователям сетей, реально используются. Большое число адресов пропадает из-за различного рода просчетов при организации подсетей, например, слишком широкая маска, или наоборот слишком "дальновидного планирования, когда в сеть закладывают большой запас "на вырост". Не следует думать, что эти адреса так и останутся невостребованными. Современное "железо" позволяет их утилизировать достаточно эффективно, но это стоит значительно дороже, чем простые способы, описанные выше. Одним словом, Internet, став действительно глобальной сетью, оказался зажатым в тисках своих собственных стандартов. Нужно было что-то срочно предпринимать, чтобы во время пика своей популярности не потерпеть сокрушительное фиаско.
В начале 1995 года IETF, после 3-x лет консультаций и дискуссий, выпустило предложения по новому стандарту протокола IP - IPv6, который еще называют IPing. К слову, следует заметить, что сейчас Internet-сообщество живет по стандарту IPv4. IPv6 призван не только решить адресную проблему, но и попутно помочь решению других задач, стоящих в настоящее время перед Internet.
Нельзя сказать, что до появления IPv6 не делались попытки обойти адресные ограничения IPv4. Например, в протоколах BOOTP (BOOTstrap Protocol) и DHCP (Dynamic Host Configuration Protocol) предлагается достаточно простой и естественный способ решения проблемы для ситуации, когда число физических подключений ограничено, или реально все пользователи не работают в сети одновременно. Типичной ситуацией такого сорта является доступ к Internet по коммутируемом каналу, например телефону. Ясно, что одновременно несколько пользователей физически не могут разговаривать по одному телефону, поэтому каждый из них при установке соединения запрашивает свою конфигурацию, в том числе и IP-адрес. Адреса выдаются из ограниченного набора адресов, который закреплен за телефонным пулом. IP-адрес пользователя может варьироваться от сессии. Фактически, DHCP - это расширение BOOTP в сторону увеличения числа протоколов, для которых возможна динамическая настройка удаленных машин. Следует заметить, что DHCP используют и для облегчения администрирования больших сетей, т.к. достаточно иметь только базу данных машин на одном компьютере локальной сети, и из нее загружать настройки удаленных компьютеров при их включении (под включением понимается, в данном случае не подключение к локальной компьютерной сети, а включение питания у компьютера, подсоединенного к сети).
Совершенно очевидно, что приведенный выше пример - это достаточно специфическое решение, ориентированное на специальный вид подключения к сети. Однако, не только адресная проблема определила появление нового протокола. Разработчики позаботились и о масштабируемой адресации IP-пакетов, ввели новые типы адресов, упростили заголовок пакета, ввели идентификацию типа информационных потоков для увеличения эффективности обмена данными, ввели поля идентификации и конфиденциальности информации.
Новый заголовок IP-пакета показан на рисунке 2.9.
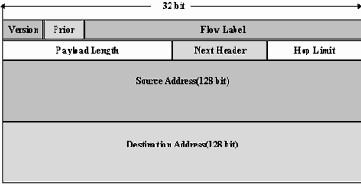
Рис. 2.9. Заголовок IPv6
В этом заголовке поле "версия" - номер версии IP, равное 6. Поле "приоритет" может принимать значения от 0 до 15. Первые 8 значений закреплены за пакетами, требующими контроля переполнения, например, 0 - несимвольная информация; 1 - информация заполнения (news), 2 - не критичная ко времени передача данных (e-mail); 4 - передача данных режима on-line (FTP, HTTP, NFS и т.п.); 6 - интерактивный обмен данными (telnet, X); 7 - системные данные или данные управления сетью (SNMP, RIP и т.п.). Поле "метка потока" предполагается использовать для оптимизации маршрутизации пакетов. В IPv6 вводится понятие потока, который состоит из пакетов. Пакеты потока имеют одинаковый адрес отправителя и одинаковый адрес получателя и ряд других одинаковых опций. Подразумевается, что маршрутизаторы будут способны обрабатывать это поле и оптимизировать процедуру пересылки пакетов, принадлежащих одному потоку. В настоящее время алгоритмы и способы использования поля "метка потока" находятся на стадии обсуждения. Поле длины пакета определяет длину следующей за заголовком части пакета в байтах. Поле "следующий заголовок" определяет тип следующего за заголовком IP-заголовка. Заголовок IPv6 имеет меньшее количество полей, чем заголовок IPv4. Многие необязательные поля могут быть указаны в дополнительных заголовках, если это необходимо. Поле "ограничение переходов" определяет число промежуточных шлюзов, которые ретранслируют пакет в сети. При прохождении шлюза это число уменьшается на единицу. При достижении значения "0" пакет уничтожается. После первых 8 байтов в заголовке указываются адрес отправителя пакета и адрес получателя пакета. Каждый из этих адресов имеет длину 16 байт. Таким образом, длина заголовка IPv6 составляет 48 байтов.
После 4 байтов IP-адреса стандарта IPv4, шестнадцать байт IP-адреса для IPv6 выглядят достаточными для удовлетворения любых потребностей Internet. Не все 2128 адресов можно использовать в качестве адреса сетевого интерфейса в сети. Предполагается выделение отдельных групп адресов, согласно специальным префиксам внутри IP-адреса, подобно тому, как это делалось при определении типов сетей в IPv4. Так, двоичный префикс "0000 010" предполагается закрепить за отображением IPX-адресов в IP-адреса. В новом стандарте выделяются несколько типов адресов: unicast addresses - адреса сетевых интерфейсов, anycast addresses - адреса не связанные с конкретным сетевым интерфейсом, но и не связанные с группой интерфейсов и multicast addresses - групповые адреса. Разница между последними двумя группами адресов в том, что anycast address это адрес конкретного получателя, но определяется адрес сетевого интерфейса только в локальной сети, где этот интерфейс подключен, а multicast-сообщение предназначено группе интерфейсов, которые имеют один multicast-адрес. Пока IPv6 не стал злобой дня, нет смысла углубляться в форматы новых IP-адресов. Отметим только, что существующие узлы Internet будут функционировать в сети без каких-либо изменений в их настройках и программном обеспечении. IPv6 предполагает две схемы включения "старых" адресов в новые. Предполагается расширять 4-х байтовый адрес за счет лидирующих байтов до 16-и байтового. При этом, для систем, которые не поддерживают IPv6, первые 10 байтов заполняются нулями, следующие два байта состоят из двоичных единиц, а за ними следует "старый" IP-адрес. Если система в состоянии поддерживать новый стандарт, то единицы в 11 и 12 байтах заменяются нулями.
Маршрутизировать IPv6-пакеты предполагается также, как и IPv4-пакеты. Однако, в стандарт были добавлены три новых возможности маршрутизации: маршрутизация поставщика IP-услуг, маршрутизация мобильных узлов и автоматическая переадресация. Эти функции реализуются путем прямого указания промежуточных адресов шлюзов при маршрутизации пакета. Эти списки помещаются в дополнительных заголовках, которые можно вставлять вслед за заголовком IP-пакета.
Кроме перечисленных возможностей, новый протокол позволяет улучшить защиту IP-трафика. Для этой цели в протоколе предусмотрены специальные опции. Первая опция предназначена для защиты от подмены IP-адресов машин. При ее использовании нужно кроме адреса подменять и содержимое поля идентификации, что усложняет задачу злоумышленника, который маскируется под другую машину. Вторая опция связана с шифрацией трафика. Пока IPv6 не стал реально действующим стандартом, говорить о конкретных механизмах шифрации трудно.
Завершая описание нового стандарта, следует отметить, что он скорее отражает современные проблемы IP-технологии и является достаточно проработанной попыткой их решения. Будет принят новый стандарт или нет покажет ближайшее будущее. Во всяком случае первые образцы программного обеспечения и "железа" уже существуют.
К канальному
уровню отнесены протоколы, определяющие соединение, например, SLIP (Strial Line Internet Protocol), PPP (Point to Point Protocol), NDIS, пакетный протокол, ODI и т.п. В данном случае речь идет о протоколе взаимодействия между драйверами устройств и устройствами, с одной стороны, а с другой стороны, между операционной системой и драйверами устройства. Такое определение основывается на том, что драйвер - это, фактически, конвертор данных из оного формата в другой, но при этом он может иметь и свой внутренний формат данных.
К сетевому
(межсетевому) уровню относятся протоколы, которые отвечают за отправку и получение данных, или, другими словами, за соединение отправителя и получателя. Вообще говоря, эта терминология пошла от сетей коммутации каналов, когда отправитель и получатель действительно соединяются на время работы каналом связи. Применительно к сетям TCP/IP, такая терминология не очень приемлема. К этому уровню в TCP/IP относят протокол IP (Internet Protocol). Именно здесь определяется отправитель и получатель, именно здесь находится необходимая информация для доставки пакета по сети.
Маршрутизация, протоколы динамической маршрутизации, средства управления маршрутами
Во всех предыдущих разделах сам механизм управления маршрутами, порождения пакетов посети старательно обходился стороной, т.к. это предмет особого разговора. Программы управления маршрутами довольно сложны, а функции, которые они выполняют, являются критичными для всей системы в целом.
Основывается система маршрутизации на таблице маршрутов, которая определяет куда пакет с данным IP-адресом следует направлять. Ниже приведен пример такой таблицы, полученный при помощи команды
Настройка Ethernet-интерфейса
В данном случае никаких параметров настраивать не надо. Следует только назначить IP-адрес. Делается это по команде
Настройка интерфейса PPP
В различных системах настройка интерфейсов PPP производится по-разному. Поэтому мы снова будем основываться на примере BSDI и FreeBSD. Для работы через PPP в этих системах используется либо демон pppd, либо прикладная программа ppp. Обычно демон используется для выделенных линий и для приема звонков на выделенном под PPP порте. Программа ppp используется для запуска из командной строки.
Для того, чтобы использовать демона в файле конфигурации ядра, необходимо определить псевдоустройство ppp(0-1). Демона помещают в файл начальной загрузки. Настройки демона производятся при помощи файла настроек:
vega-gw: {6} cat options /dev/cuaa2 57600 194.190.135.22:194.190.135.21 netmask 255.255.255.252 passive defaultroute #debug local #kdebug 7
В данном примере мы используем файл /etc/ppp/options. В нем определяется порт, через который настраивается интерфейс, скорость на порте, адрес интерфейса и адрес ответного интерфейса провайдера, маска, установленная на сети провайдера, команда passive, которая заставляет оставлять данный интерфейс постоянно в таблице маршрутов, определение его как шлюза по умолчанию, и определяет его управление с локальной машины. Кроме этого, в данном файле есть еще и закомментированные опции, которые использовались автором во время отладки соединения. Включение этих двух опций приводит к полному дампированию пакетов PPP, что позволяет выяснить причины отсутствия соединения или плохого соединения.
В данном случае мы отлаживали соединение с relarn, где на конце relarn пакеты принимал маршрутизатор CISCO.
Если надо устанавливать соединение с удаленной машины со шлюзом, то вместо SLIP можно также использовать PPP. Но только в этом случае лучше всего использовать программу ppp. Она также настраивается через свой файл конфигурации, пример которого приведен ниже:
vega-gw: {7} cat ppp.conf default: set device /dev/cuaa0 set speed 38400 disable lqr deny lqr # set debug level LCP relarn: set ifaddr 194.190.135.22 194.190.135.21 add 0 255.255.255.252 194.190.135.21
Надеюсь, что значение параметров в этом файле понятно и без лишних комментариев.
Главной особенностью программы ppp является то, что ее можно запустить в интерактивном режиме, по мере ее работы менять тип информации, который подлежит отладке.
При использовании и ppp, и pppd команды ifconfig на интерфейсы выдавать не надо, т.к. эти команды сами производят их настройку.
В заключении разговора о настройке интерфейсов приведем пример таблицы интерфейсов с машины, где работает сразу три разных интерфейса:
vega-gw: {9} netstat -ain Name Mtu Network Address Ipkts Ierrs Opkts Oerrs Coll ed1 1500 <Link>00.20.c5.00.35.c4 10574 0 10223 0 2 ed1 1500 194.226.43 194.226.43.1 10574 0 10223 0 2 lp0* 1500 <Link> 0 0 0 0 0 lo0 16384 <Link> 357 0 357 0 0 lo0 16384 127 127.0.0.1 357 0 357 0 0 ppp0 1500 <Link> 58000 0 55347 0 0 ppp0 1500 194.190.135 194.190.135.22 58000 0 55347 0 0 ppp1* 1500 <Link> 0 0 0 0 0 sl0* 552 <Link> 20570 1 21281 0 0 sl0* 552 194.226.43 194.226.43.99 20570 1 21281 0 0 sl1* 552 <Link> 0 0 0 0 0 tun0* 1500 <Link> 0 0 0 0 0
В этой таблице можно найти интерфейс Ethernet (ed1), интерфейс PPP (ppp0) и интерфейс SLIP (sl1), которые находятся в активном состоянии и принимают и отправляют пакеты.
Через интерфейс ed1 (IP-адрес: 144.226.43.1) доступна сеть 144.226.43.0, через интерфейс ppp0 (IP-адрес: 194.190.135.22) доступна сеть 144.190.135.0, которая является путем в Internet, через sl0 (IP-адрес: 194.226.43.99) работает удаленный пользователь.
Настройка операционной системы и сетевые интерфейсы
Прежде чем начать описание настроек сетевых интерфейсов, обратим свое внимание на особенности операционной системы, которая должна работать с сетью TCP/IP. Чаще всего при этом подразумевается операционная система Unix. Мы не будем отступать от этой традиции. Рассмотрим настройку ОС вручную, а не с использованием диалоговых средств, которые широко применяются в HP-UX, IRIX, SCO и т. п. В Unix все равно все сводится к выполнению тех же самых команд, но только программами или скриптами. Администратор всегда может воспользоваться интерфейсом командной строки, чтобы поправить настройки, выполненные ранее рекомендованными в руководстве по администрированию средствами.
Для того, чтобы система работала со стеком протоколов TCP/IP необходимо соответствующим образом настроить ядро системы. В системах клона BSD конфигурация определяется в фале типа /usr/sys/conf, Например, во FreeBSD 2.x, - это файл /sys/i386/conf/GE-NERIC, если речь идет о только что установленной системе.
Обычно, на основе этого файла делают копию, которую называют local, и в этой копии проводят изменения настроек. В этом файле следует определить, чаще всего раскомментировать, строки, которые определяют сетевые интерфейсы, например, ed0 или ed1, если речь идет о Ethernet. Кроме этого, если машина будет работать шлюзом, нужно указать опцию GATEWAY, если нужно использовать распределенную файловую систему, то нужно заказать также соответствующие опции. Для таких протоколов, как SLIP и PPP, нужно определить еще и псевдоустройства. Ниже приведен пример такого файла конфигурации, точнее фрагмент.
Файл конфигурации ядра FreeBSD 2.x.
quest:/usr/src/sys/i386/conf:\[6\]>cat QUEST options NFS #Network File System options GATEWAY #Host is a Gateway (forwards packets) device sio0 at isa? port "IO_COM1" tty irq 4 vector siointr device sio1 at isa? port "IO_COM2" tty irq 3 vector siointr device lpt0 at isa? port? tty irq 7 vector lptintr device ed0 at isa? port 0x280 net irq 9 iomem 0xd8000 vector edintr device ed1 at isa? port 0x300 net irq 5 iomem 0xd8000 vector edintr pseudo-device loop pseudo-device ether pseudo-device log pseudo-device sl 2
Из этого фрагмента видно, что данная машина позволяет работать с распределенной файловой системой, является шлюзом, имеет два сетевых интерфейса Ethernet: ed0 и ed1, а также еще два интерфейса на последовательных портах: sl0 и sl1, что соответствует портам sio0 и sio1.
Для того, чтобы данная конфигурация была реализована, надо пересобрать ядро. Для этого выполняется процедура генерации make-файлов, и после этого выполняется программа make. Как только новое ядро собрано его можно копировать в корень на место существующего ядра, но при этом надо не забыть сохранить старое ядро. Обычно Unix позволяет указать при загрузке имя файла ядра, что позволит загрузиться на машине, новое ядро которой оказалось неработоспособным.
В системах клона System 5, настройки ядра распределены по многим фалам. Здесь лучше воспользоваться стандартными средствами конфигурации типа SAM в HP-UX, т.к. можно просто забыть что-нибудь подправить.
При настройках Windows NT систему можно сконфигурировать для работы с сетями TCP/IP как при установке, так и потом, по мере необходимости. Правда отложенная конфигурация приведет к перезагрузке системы. Настраивается сеть из меню network в меню control panel. Там также определяется тип интерфейса и копируется с дистрибутива драйвер для данного интерфейса. Потом для интерфейса определяется семейство протоколов, где среди протоколов Microsoft можно найти и TCP/IP. Далее интерфейсу назначается IP-адрес, определяется шлюз и сервер доменных имен. Другие параметры, типа сервиса WINS (Windows Internet Name System), мы рассматривать не будем, т.к. это касается только Windows, а не Internet вообще.
При установке стека TCP/IP на машины с операционной системой MS-DOS следует иметь в виду, что здесь надо установить все выше описанное, но только в отличии от выше перечисленных операционных систем все программное обеспечение является прикладными задачами, а не частью операционной системы, поэтому никакой перенастройки ядра не происходит. Общая схема машины с OC MS-DOS, поддерживающей стек TCP/IP будет выглядеть так, как показано на рисунке 2.23.
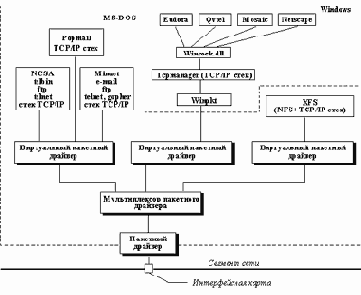
Рис. 2.23. Структура стека программного обеспечения для поддержки стека протоколов TCP/IP на персональном компьютере
Естественно, что все эти модули, которые представлены на рисунке 2.23 должны быть указаны в файлах config.sys и autoexec.bat. Примеры содержания файлов autoexec.bat и config.sys приведены ниже и основаны они на настройке персонального компьютера notebook, который работает с сетью либо через сетевой PCMCI-адаптер Ethernet, либо через PCMCI-модем, что и отражено в вариантной загрузке.
Пример файла autoexec.bat
@ECHO OFF set tz=MSK set temp=c:\temp set tmp=c:\temp PATH C:\WINWORD;C:\;C:\NC5;C:\WINDOWS;C:\DOS;C:\UT;C:\ME;c:\spelchek\g4; c:\spelchek\logs;c:\photo; goto %config% :Network PATH %PATH%c:\network\tel;c:\network\xfs; :Dial-in :Local LH CYRILLIC LH C:\DOS\SHARE.EXE /l:500 /f:5100 nc
При работе через сетевой адаптер все интерфейсы устанавливаются только в config.sys, а в autoexec.bat подправляется только переменная окружения PATH.
Содержание файла config.sys
[menu] menuitem=Local, Load Computer without any drivers. menuitem=Network, Start Computer with Ethernet Network Conection. menuitem=Dial-in, Start Computer in Local Mode with Dial-in Connection. [common] rem common statments [Local] rem ordinal [Network] rem network interface installation device=c:\network\pktdrv\accopen.exe /int=5 /port=300 /mem=0000 DEVICE=C:\DOS\HIMEM.SYS DEVICE=c:\dos\emm386.exe noems
[Dial-in] DEVICE=C:\DOS\HIMEM.SYS DEVICE=c:\dos\emm.386.exe noems ; PCMCI modem DEVICEHIGH=C:\PCMCIA\SSVADEM.SYS DEVICEHIGH=C:\PCMCIA\AMICS.SYS DEVICEHIGH=C:\PCMCIA\PCMODEM.SYS
Впрочем, для различных систем и для различных пакетов, настройки могут довольно сильно отличаться, но структура всегда будет одной и той же.
Таким образом, после сборки нового ядра в системах Unix и Windows NT, или после выполнения настройки MS-DOS в системе появляются сетевые интерфейсы, стек протоколов TCP/IP и возможность совместной настройки интерфейсов и стека протоколов.
Настройка сетевых интерфейсов
Настройкой сетевых интерфейсов называют определение параметров обмена данными через сетевой интерфейс и присвоение ему IP-адреса. Сначала разберем, как это делается для интерфесов Ethernet, а потом уже для последовательных портов.
Настройка SLIP
С последовательным портом работают через псевдоустройство sl0, которое и является интерфейсом последовательного порта. Для сцепления sl0 c устройством служит команда
Основные принципы IP-маршрутизации
Как уже было сказано раньше, протокол IP не является протоколом ориентированным на соединение. Следовательно, решение о направлении IP-пакета на тот или иной сетевой интерфейс принимается шлюзом в момент прохождения через него пакета. Данное решение принимается на основании таблицы маршрутов, имеющаяся на каждом компьютере, который поддерживает стек протоколов TCP/IP.
Прежде чем перейти к описанию самой процедуры, введем пример сети, на которой будем рассматривать маршрутизацию пакетов (рисунок 2.21).
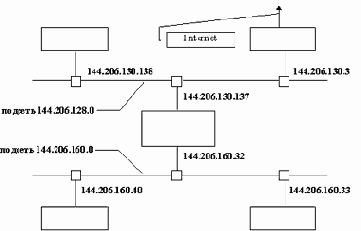
Рис. 2.21. Пример фрагмента локальной сети
На рисунке 2.21 изображены два фрагмента подсетей (144.206.160.0 и 144.206.128.0) сети класса B (144.206.0.0). Машина с интерфейсами, которые имеют адреса 144.206.160.32 и 144.206.130.137 - это шлюз между двумя подсетями, а машина с адресом сетевого интерфейса 144.206.130.3 - это шлюз сети с другой сетью, которая подключена к Internet.
Рассмотрим сначала путь пакета от машины с адресом 144.206.160.40 к машине с адресом 144.206.160.33. Предположим, что к этой машине пользователь 144.206.160.40 еще не обращался. В рамках такого обмена машине достаточно знать только свой IP-адрес. Прежде чем отправить пакет, модуль ARP проверит, существует ли соответствие между IP-адресом получателя и физическим адресом какого-либо интерфейса включенного в локальную сеть. В нашем случае такого соответствия еще нет, поэтому в сеть будет отправлен широковещательный запрос на получение физического адреса по заданному IP-адресу. В ответ машина 144.206.160.33 сообщит свой адрес, после чего пакет будет отправлен в сеть. В поле физического адреса в фрейме протокола канального уровня будет указан адрес машины 144.206.160.33. Вообще говоря, такая процедура была разработана для Ethernet, но в последнее время ARP стали применять и для других физических сред, в частности, для FrameRelay.
Теперь отправим пакет машине из другой подсети 144.206.130.138. В этом случае на широковещательный запрос мы ответа не получим. Но пакет отправлять как-то надо. Для этой цели в описании маршрутов пакетов всегда есть IP-адрес, на который следует отправлять пакеты по умолчанию, если нет другого способа их рассылки. Естественно, что это адрес шлюза. Для машины 144.206.160.40 таким адресом является адрес 144.206.160.32. Физический адрес этого интерфейса получают точно также, как мы до этого получили физический адрес интерфейса 144.206.160.33. Принципиальное различие здесь заключается в том, что в первом случае адреса получателя и отправителя во фрейме физического протокола совпадали с адресами, которые указаны для IP-адресов из IP-пакета в таблице ARP. В случае шлюза здесь можно обнаружить несоответствие. Во фрейме в качестве получателя будет указан адрес интерфеса 144.206.160.32, в то время как в IP-пакете будет указан IP-адрес 144.206.130.138. Но ведь этому IP-адресу соответствует совсем другой физический адрес. Если быть более точным, то другой адрес будет соответствовать в сети Ethernet, если же речь идет о FrameRelay, то там может применяться относительная система адресации, что может приводить к равенству физических адресов.
Получив таким образом пакет модуль IP машины шлюза определяет, что это не его адрес указан в IP-пакете. После такого открытия IP-модуль шлюза принимает решение о дальнейшей отправке пакета. Отправлять пакет в тот же интерфейс, из которого он получен - бессмысленно, поэтому модуль IP никогда не отправляет пакеты назад. Следовательно, происходит поиск нужного интерфейса и через него снова рассылается широковещательный запрос ARP. В нашем случае такой запрос вернет для IP-адреса 144.206.130.138 физический адрес машины и пакет будет отправлен по этому адресу.
Если пакет отправляется в Internet, то шлюз не найдет физического адреса машины, и будет вынужден воспользоваться адресом рассылки по умолчанию. Таким образом, пакет попадет на шлюз через 144.206.130.3 и там будет решаться его судьба.
При рассмотрении стека протоколов TCP/IP на компьютере с одним сетевым интерфейсом было не очень понятно, зачем IP дублирует физический адрес, например, Ethernet, ведь каждому адресу Ethernet ставился в соответствие один IP-адрес. При рассмотрении архитектуры стека протоколов шлюза этот вопрос становится более понятным.
Из рисунка 2.22 видно, что таблица ARP создается для каждого интерфейса. Для получения таких таблиц можно использовать команду arp, где в качестве аргумента надо указать имя интерфейса. Модуль IP для шлюза общий и таблица маршрутов, а именно, она и используется модулем для перенаправления пакетов на интерфейсы, также общая.
Прежде чем перейти к описанию таблицы маршрутов и способам управления ею, обратим свое внимание на способы настройки сетевых интерфейсов, т.к. без них никакой стек протоколов работать с сетью не будет.
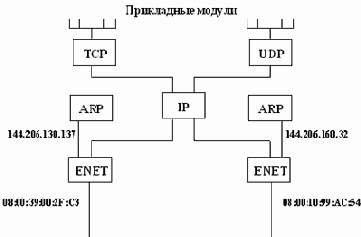
Рис. 2.22. Архитектура шлюза 144.206.130.137-144.206.160.32
Основные протоколы стека TCP/IP
При описании основных протоколов стека TCP/IP будем следовать модели стека описанной в предыдущем разделе. Первыми будут рассмотрены протоколы канального ровня SLIP и PPP. Это единственные протоколы этого уровня которые будут нами рассмотрены, так как были разработаны в рамках Internet и для Internet. Другие протоколы, например, NDIS или ODI, мы рассматривать не будем, т.к. они создавались под другие сети, хотя и могут использоваться в сетях TCP/IP также, как например, и пакетный протокол.
Основы межсетевого обмена в сетях TCP/IP
Сеть Internet - это сеть сетей, объединяющая как локальные сети, так и глобальные сети типа NSFNET. Поэтому центральным местом при обсуждении принципов построения сети является семейство протоколов межсетевого обмена TCP/IP.
Под термином "TCP/IP" обычно понимают все, что связано с протоколами TCP и IP. Это не только собственно сами проколы с указанными именами, но и протоколы построенные на использовании TCP и IP, и прикладные программы.
Главной задачей стека TCP/IP является объединение в сеть пакетных подсетей через шлюзы. Каждая сеть работает по своим собственным законам, однако предполагается, что шлюз может принять пакет из другой сети и доставить его по указанному адресу. Реально, пакет из одной сети передается в другую подсеть через последовательность шлюзов, которые обеспечивают сквозную маршрутизацию пакетов по всей сети. В данном случае, под шлюзом понимается точка соединения сетей. При этом соединяться могут как локальные сети, так и глобальные сети. В качестве шлюза могут выступать как специальные устройства, маршрутизаторы, например, так и компьютеры, которые имеют программное обеспечение, выполняющее функции маршрутизации пакетов. Маршрутизация - это процедура определения пути следования пакета из одной сети в другую.
Такой механизм доставки становится возможным благодаря реализации во всех узлах сети протокола межсетевого обмена IP. Если обратиться к истории создания сети Internet, то с самого начала предполагалось разработать спецификации сети коммутации пакетов. Это значит, что любое сообщение, которое отправляется по сети, должно быть при отправке "нашинковано" на фрагменты. Каждый из фрагментов должен быть снабжен адресами отправителя и получателя, а также номером этого пакета в последовательности пакетов, составляющих все сообщение в целом. Такая система позволяет на каждом шлюзе выбирать маршрут, основываясь на текущей информации о состоянии сети, что повышает надежность системы в целом. При этом каждый пакет может пройти от отправителя к получателю по своему собственному маршруту. Порядок получения пакетов получателем не имеет большого значения, т.к. каждый пакет несет в себе информацию о своем месте в сообщении. При создании этой системы принципиальным было обеспечение ее живучести и надежной доставки сообщений, т.к. предполагалось, что система должна была обеспечивать управление Вооруженными Силами США в случае нанесения ядерного удара по территории страны.
Подсеть
- это подмножество сети, не пересекающееся с другими подсетями. Это означает, что сеть организации (скажем, сеть класса С) может быть разбита на фрагменты, каждый из которых будет составлять подсеть. Реально, каждая подсеть соответствует физической локальной сети (например, сегменту Ethernet). Вообще говоря, подсети придуманы для того, чтобы обойти ограничения физических сетей на число узлов в них и максимальную длину кабеля в сегменте сети. Например, сегмент тонкого Ethernet имеет максимальную длину 185 м и может включать до 32 узлов. Как видно из рисунка 2.15, самая маленькая сеть - класса С - может состоять из 254 узлов. Для того, чтобы достичь этой цифры, надо объединить несколько физических сегментов сети. Сделать это можно либо с помощью физических устройств (например, репитеров), либо при помощи машин-шлюзов. В первом случае разбиения на подсети не требуется, т.к. логически сеть выглядит как одно целое. При использовании шлюза сеть разбивается на подсети (рисунок 2.17).
На рисунке 2.17 изображен фрагмент сети класса B - 144.206.0.0, состоящий из двух подсетей - 144.206.130.0 и 144.206.160.0. В центре схемы изображена машина шлюз, которая связывает подсети. Эта машина имеет два сетевых интерфейса и, соответственно, два IP-адреса.
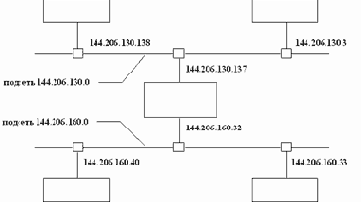
Рис. 2.17. Схема разбиения адресного пространства сети на подсети
В принципе, разбивать сеть на подсети необязательно. Можно использовать адреса сетей другого класса (с меньшим максимальным количеством узлов). Но при этом возникает, как минимум, два неудобства:
В сети, состоящей из одного сегмента Ethernet, весь адресный пул сети не будет использован, т.к., например, для сети класса С (самой маленькой с точки зрения количества узлов в ней), из 254 возможных адресов можно использовать только 32; Все машины за пределами организации, которым разрешен доступ к компьютерам сети данной организации, должны знать шлюзы для каждой из сетей. Структура сети становится открытой во внешний мир. Любые изменения структуры могут вызвать ошибки маршрутизации. При использовании подсетей внешним машинам надо знать только шлюз всей сети организации. Маршрутизация внутри сети - это ее внутреннее дело.
Разбиение сети на подсети использует ту часть IP-адреса, которая закреплена за номерами хостов. Администратор сети может замаскировать часть IP-адреса и использовать ее для назначения номеров подсетей. Фактически, способ разбиения адреса на две части, теперь будет применятся к адресу хоста из IP-адреса сети, в которой организуется разбиение на подсети.
Маска подсети - это четыре байта, которые накладываются на IP-адрес для получения номера подсети. Например, маска 255.255.255.0 позволяет разбить сеть класса В на 254 подсети по 254 узла в каждой. На рисунке 2.18 приведено маскирование подсети 144.206.160.0 из предыдущего примера.
На приведенной схеме (рисунок 2.18) сеть класса B (номер начинается с 10) разбивается на подсети маской 255.255.224.0. При этом первые два байта задают адрес сети и не участвуют в разбиении на подсети. Номер подсети задается тремя старшими битами третьего байта маски. Такая маска позволяет получить 6 подсетей. Для нумерации подсети нельзя использовать номер 000 и номер 111. Номер 160 задает 5-ю подсеть в сети 144.206.0.0. Для нумерования машин в подсети можно использовать оставшиеся после маскирования 13 битов, что позволяет создать подсеть из 8190 узлов. Честно говоря, в настоящее время такой сети в природе не существует и РНЦ "Курчатовский Институт", которому принадлежит сеть 144.206.0.0, рассматривает возможность пересмотра маски подсетей. Перестроить сеть, состоящую из более чем 400 машин, не такая простая задача, так как ей управляет 4 администратора, которые должны изменить маски на всех машинах сети. Ряд компьютеров работает в круглосуточном режиме и все изменения надо произвести в тот момент, когда это минимально скажется на работе пользователей сети. Данный пример показывает насколько внимательно следует подходить к вопросам планирования архитектуры сети и ее разбиения на подсети. Многие проблемы можно решить за счет аппаратных средств построения сети.
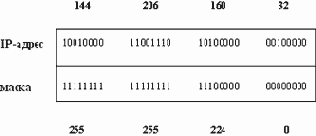
Рис. 2.18. Схема маскирования и вычисления номера подсети
К сожалению, подсети не только решают, но также и создают ряд проблем. Например, происходит потеря адресов, но уже не по причине физических ограничений, а по причине принципа построения адресов подсети. Как было видно из примера, выделение трех битов на адрес подсети не приводит к образованию 8-ми подсетей. Подсетей образуется только 6, так как номера сетей 0 и 7 использовать в силу специального значения IP-адресов, состоящих из 0 и единиц, нельзя. Таким образом, все комбинации адресов хоста внутри подсети, которые можно было бы связать с этими номерами, придется забыть. Чем шире маска подсети (чем больше места отводится на адрес хоста), тем больше потерь. В ряде случаев приходится выбирать между приобретением еще одной сети или изменением маски. При этом физические ограничения могут быть превышены за счет репитеров, хабов и т. п.
Подсети
Важным элементом разбиения адресного пространства Internet являются подсети.
Порты и сокеты
После того, как мы разобрались с основными протоколами и IP-адресами, не плохо было бы понять, как все это вместе стыкуется и работает. В заголовках протоколов нет наименований протоколов, а есть только номера. Кроме того, данные каждому приложению также доставляются с использованием номеров, которые называются портами. Пара - протокол и порт - позволяет стеку протоколов TCP/IP доставить данные нуждающемуся в них приложению. Увидеть номера протоколов можно в файле
rn Routing tables Destination Gateway
Таблица маршрутов
quest:/usr/src/sys/i386/conf:\[16\]>netstat - rn Routing tables Destination Gateway Flags Refs Use IfaceMTU Rtt Netmasks: (root node) (0) 0000 ff00 (0) 0000 ffff e000 (root node) Route Tree for Protocol Family inet: (root node) => default 144.206.136.12 UG 1 1081 ed1 - - 127 127.0.0.1 UR 0 0 lo0 - - 127.0.0.1 127.0.0.1 UH 0 51 lo0 - - 144.206 144.206.131.5 UG 0 0 ed1 - - 144.206.64 144.206.136.230 UG 0 0 ed1 - - 144.206.96 144.206.130.135 UG 0 0 ed1 - - 144.206.128 144.206.130.138 U 2 9900 ed1 - - 144.206.192 144.206.192.1 U 2 26203 ed0 - - 194.226.56 144.206.130.207 UGD 0 0 ed1 - - (root node) quest:/usr/src/sys/i386/conf:\[17\]>
В данном примере в левой колонке указаны адреса возможных IP-адресов, которые система принимает из сети, далее идет адрес шлюза для данных адресов, затем флаги маршрутизации, степень использования данного маршрута и интерфейс, на котором данный маршрут обслуживается.
Однако, наша таблица не дает ответа на степень изменчивости данной таблицы. Для этого нам придется снова вернуться к изучению протоколов, но только теперь уже протоколов маршрутизации.
Принципы построения IP-адресов
IP-адреса определены в том же самом RFC, что и протокол IP. Именно адреса являются той базой, на которой строится доставка сообщений через сеть TCP/IP.
IP-адрес - это 4-байтовая последовательность. Принято каждый байт этой последовательности записывать в виде десятичного числа. Например, приведенный ниже адрес является адресом одной из машин РНЦ "Курчатовский Институт": 144.206.160.32
Каждая точка доступа к сетевому интерфейсу имеет свой IP-адрес.
IP-адрес состоит из двух частей: адреса сети и номера хоста. Вообще говоря, под хостом понимают один компьютер, подключенный к Сети. В последнее время, понятие "хост" можно толковать более расширено. Это может быть и принтер с сетевой картой, и Х-терминал, и вообще любое устройство, которое имеет свой сетевой интерфейс.
Существует 5 классов IP-адресов. Эти классы отличаются друг от друга количеством битов, отведенных на адрес сети и адрес хоста в сети. На рисунке 2.14 показаны эти пять классов.
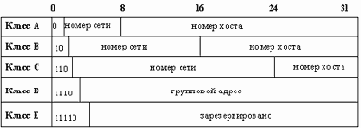
Рис. 2.14. Классы IP-адресов
Опираясь на эту структуру, можно подсчитать характеристики каждого класса в терминах числа сетей и числа машин в каждой сети.
| Класс | Диапазон значений первого октета | Возможное количество сетей | Возможное количество узлов |
| А | 1 - 126 | 126 | 16777214 |
| B | 128 - 191 | 16382 | 65534 |
| C | 192 - 223 | 2097150 | 254 |
| D | 224 - 239 | - | 228 |
| E | 240 - 247 | - | 227 |
Рис. 2.15. Характеристики классов IP-адресов
При разработке структуры IP-адресов предполагалось, что они будут использоваться по разному назначению.
Адреса класса A предназначены для использования в больших сетях общего пользования. Адреса класса B предназначены для использования в сетях среднего размера (сети больших компаний, научно-исследовательских институтов, университетов). Адреса класса C предназначены для использования в сетях с небольшим числом компьютеров (сети небольших компаний и фирм). Адреса класса D используют для обращения к группам компьютеров, а адреса класса E - зарезервированы.
Среди всех IP-адресов имеется несколько зарезервированных под специальные нужды. Ниже приведена таблица зарезервированных адресов.
| IP-адрес | Значение |
| все нули | данный узел сети |
| номер сети | все нули | данная IP-сеть |
| все нули | номер узла | узел в данной (локальной) сети |
| все единицы | все узлы в данной локальной IP-сети |
| номер сети | все единицы | все узлы указанной IP-сети |
| 127.0.0.1 | "петля" |
Рис. 2.16. Выделенные IP-адреса
Особое внимание в таблице (рисунок 2.16) уделяется последней строке. Адрес 127.0.0. 1 предназначен для тестирования программ и взаимодействия процессов в рамках одного компьютера. В большинстве случаев в файлах настройки этот адрес обязательно должен быть указан, иначе система при запуске может зависнуть (как это случается в SCO Unix). Наличие "петли" чрезвычайно удобно с точки зрения использования сетевых приложений в локальном режиме для их тестирования и при разработке интегрированных систем.
Вообще, зарезервирована вся сеть 127.0.0.0. Эта сеть класса A реально не описывает ни одной настоящей сети.
Некоторые зарезервированные адреса используются для широковещательных сообщений. Например, номер сети (строка 2) используется для посылки сообщений этой сети (т.е. сообщений всем компьютерам этой сети). Адреса, содержащие все единицы, используются для широковещательных посылок (для запроса адресов, например).
Реальные адреса выделяются организациями, предоставляющими IP-услуги, из выделенных для них пулов IP-адресов. Согласно документации NIC (Network Information Centre) IP-адреса предоставляются бесплатно, но в прейскурантах наших организаций (как коммерческих, так и некоммерческих), занимающихся Internet-сервисом предоставление IP-адреса стоит отдельной строкой.
Программа routed
Программа routed поставляется с любым клоном Unix и используется в качестве демона протокола RIP по умолчанию. Как правило, она используется без аргументов и запускается в момент загрузки операционной системы. Однако, если машина не является шлюзом, то имеет смысл указать флаг "-q". Этот флаг означает, что routed не будет посылать информации в сеть, а только будет слушать информацию от других машин. Обычно, активными являются шлюзы, а все остальные системы являются пассивными.
Однако, часто бывает полезно при начальной загрузке инициализировать таблицу маршрутов и определить строки, которые из нее не следует удалять ни при каких условиях. Самый типичный случай - назначение шлюза по умолчанию. Для этой цели можно использовать файл /etc/gateways, который программа routed просматривает при запуске и использует для первоначальной настройки таблицы маршрутов. Содержание этого файла может выглядеть следующим образом:
net 0.0.0.0 gateway 144.206.136.10 netric 1 passive
В данном примере адрес 0.0.0.0 используется для определения адреса умолчания, машина 144.206.136.10 - это шлюз по умолчанию, метрика определяет число hop'ов до этого шлюза, а параметр "passive" - говорит о том, что даже если с этого шлюза никакой информации о маршрутах не приходит, то его все равно не надо удалять из таблицы маршрутов. Последний параметр указывается в том случае, если шлюз только один, если же возможно использование другого шлюза и эти шлюзы активно извещают машины сети о своих таблицах маршрутов, то следует вместо passive использовать active: net 0.0.0.0 gateway 144.206.136.10 netric 1 active
В этом случае пассивный шлюз из таблицы маршрутов будет удален, а тот, который может исполнять функции реального шлюза будет в таблицу включен. В сети kiae изменение шлюза по умолчанию можно наблюдать по несколько раз в день.
Когда используется только Ethernet, то программа routed может использоваться и на машинах шлюзах, но если система связана с внешним миром через SLIP или PPP, то использование routed может привести к потере самого главного маршрута. Он будет удален из таблицы из соображений неактивности. В этом случае лучше всего использовать программу gated.
Протокол ARP. Отображение канального уровня на уровень межсетевого обмена
Прежде чем начать описание протокола ARP необходимо сказать несколько слов о протоколе Ethernet.
Протокол ARP (RFC 826)
. Address Resolution Protocol используется для определения соответствия IP-адреса адресу Ethernet. Протокол используется в локальных сетях. Отображение осуществляется только в момент отправления IP-пакетов, так как только в этот момент создаются заголовки IP и Ethernet. Отображение адресов осуществляется путем поиска в ARP-таблице. Упрощенно, ARP-таблица состоит из двух столбцов:
| IP-адрес | Ethernet-адрес |
| 223.1.2.1 | 08:00:39:00:2F:C3 |
| 223.1.2.3 | 08:00:5A:21:A7:22 |
| 223.1.2.4 | 08:00:10:99:AC:54 |
В первом столбце содержится IP-адрес, а во втором Ethernet-адрес. Таблица соответствия необходима, так как адреса выбираются произвольно и нет какого-либо алгоритма для их вычисления. Если машина перемещается в другой сегмент сети, то ее ARP-таблица должна быть изменена.
Таблицу ARP можно посмотреть, используя команду arp:
quest:/usr/paul:\[8\]%arp -a paul.polyn.kiae.su (144.206.192.34) at 0:0:1:16:2:45 polyn.net.kiae.su (144.206.130.137) at 0:1:1b:9:d0:90 arch.kiae.su (144.206.136.10) at 0:0:c:1b:ae:7b demin.polyn.kiae.su (144.206.192.4) at 0:0:1:16:29:80 quest:/usr/paul:\[9\]%
Правда здесь существуют нюансы. В каждый момент времени таблица ARP разная. Это хорошо видно на следующем примере:
Ix: {8} arp -a polyn.net.kiae.su (144.206.130.137) at 0:1:1b:9:d0:90 permanent quest.net.kiae.su (144.206.130.138) at 0:0:1b:12:32:32 ? (144.206.140.201) at 0:0:c0:89:c4:a4 polyn.net.kiae.su (144.206.160.32) at 0:80:29:b1:9f:e3 permanent Ix.polyn.kiae.su (144.206.160.33) at (incomplete) Ix: {9} ping apollo.polyn.kiae.su PING apollo.polyn.kiae.su (144.206.160.40): 56 data bytes 64 bytes from 144.206.160.40: icmp_seq=0 ttl=255 time=1.409 ms 64 bytes from 144.206.160.40: icmp_seq=1 ttl=255 time=0.799 ms 64 bytes from 144.206.160.40: icmp_seq=2 ttl=255 time=0.797 ms 64 bytes from 144.206.160.40: icmp_seq=3 ttl=255 time=0.857 ms ^C --- apollo.polyn.kiae.su ping statistics --- 4 packets transmitted, 4 packets received, 0% packet loss round-trip min/avg/max = 0.797/0.965/1.409 ms Ix: {10} arp -a polyn.net.kiae.su (144.206.130.137) at 0:1:1b:9:d0:90 permanent quest.net.kiae.su (144.206.130.138) at 0:0:1b:12:32:32 ? (144.206.140.201) at 0:0:c0:89:c4:a4 polyn.net.kiae.su (144.206.160.32) at 0:80:29:b1:9f:e3 permanent Ix.polyn.kiae.su (144.206.160.33) at (incomplete) apollo.polyn.kiae.su (144.206.160.40) at 8:0:9:b:3d:b8 Ix: {11}
В приведенном примере подчеркиванием выделены команды, которые пользователь вводил из командной строки. При первом использовании команды ARP в таблице ARP нет машины apollo.polyn.kiae.su, хотя она находится в том же сегменте Ethernet, что и машина polyn.net.kiae.su, на которой выполняются команды. После выполнения команды ping в таблицу добавляется новая строка, которая задает соответствие Ethernet-адреса машины apollo и ее IP-адреса.
Кроме этого, в обоих отчетах arp есть строка с пустым именем машины, а точнее символом "?" в имени машины. В разделе 3.1 будут подробно рассмотрены вопросы определения имени машины по IP-адресу и IP-адреса по имени машины. В данном случае для машины с адресом 144.206.140.201 просто не определено соответствие между IP-адресом и именем машины.
При работе в локальной IP-сети при обращении к какому-либо ресурсу, например архиву FTP, его Ethernet-адрес ищется по IP-адресу в ARP-таблице и после этого запрос отправляется на сервер.
ARP-таблица заполняется автоматически, что хорошо видно из приведенного ранее примера. Если нужного адреса в таблице нет, то в сеть посылается широковещательный запрос типа "чей это IP-адрес?". Все сетевые интерфейсы получают этот запрос, но отвечает только владелец адреса. При этом существует два способа отправки IP-пакета, для которого ищется адрес: пакет ставится в очередь на отправку или уничтожается. В первом случае за отправку отвечает модуль ARP, а во втором случае модуль IP, который повторяет посылку через некоторое время. Широковещательный запрос выглядит так:
| IP-адрес отправителя | 223.1.2.1 |
| Ethernet-адрес отправителя | 08:00:39:00:2F:C3 |
| Искомый IP-адрес | 222.1.2.2 |
| Искомый Ethernet-адрес | <пусто> |
| IP-адрес отправителя | 222.1.2.2 |
| Ethernet-адрес отправителя | 08:00:28:00:38:А9 |
| IP-адрес получателя | 223.1.2.1 |
| Ethernet-адрес получателя | 08:00:39:00:2F:C3 |
Следует отметить, что если искомого IP-адреса нет в локальной сети и сеть не соединена с другой сетью шлюзом, то разрешить запрос не удается. IP-модуль будет уничтожать такие пакеты, обычно по time-out (превышен лимит времени на разрешение запроса). Модули прикладного уровня, при этом, не могут отличить физического повреждения сети от ошибки адресации.
Однако в современной сети Internet, как правило, запрашивается информация с узлов, которые реально в локальную сеть не входят. В этом случае для разрешения адресных коллизий и отправки пакетов используется модуль IP.
Если машина соединена с несколькими сетями, т.е. она является шлюзом, то в таблицу ARP вносятся строки, которые описывают как одну, так и другую IP-сети. При использовании Ethernet и IP каждая машина имеет как минимум один адрес Ethernet и один IP-адрес. Собственно Ethernet-адрес имеет не компьютер, а его сетевой интерфейс. Таким образом, если компьютер имеет несколько интерфейсов, то это автоматически означает, что каждому интерфейсу будет назначен свой Ethernet-адрес. IP-адрес назначается для каждого драйвера сетевого интерфейса. Грубо говоря, каждой сетевой карте Ethernet соответствуют один Ethernet-адрес и один IP-адрес. IP-адрес уникален в рамках всего Internet.
Протокол IP
Протокол IP является самым главным во всей иерархии протоколов семейства TCP/IP. Именно он используется для управления рассылкой TCP/IP пакетов по сети Internet. Среди различных функций, возложенных на IP обычно выделяют следующие:
определение пакета, который является базовым понятием и единицей передачи данных в сети Internet. Многие зарубежные авторы называют такой IP-пакет датаграммой; определение адресной схемы, которая используется в сети Internet; передача данных между канальным уровнем (уровнем доступа к сети) и транспортным уровнем (другими словами мультиплексирование транспортных датаграмм во фреймы канального уровня); маршрутизация пакетов по сети, т.е. передача пакетов от одного шлюза к другому с целью передачи пакета машине-получателю; "нарезка" и сборка из фрагментов пакетов транспортного уровня.
Главными особенностями протокола IP является отсутствие ориентации на физическое или виртуальное соединение. Это значит, что прежде чем послать пакет в сеть, модуль операционной системы, реализующий IP, не проверяет возможность установки соединения, т.е. никакой управляющей информации кроме той, что содержится в самом IP-пакете, по сети не передается. Кроме этого, IP не заботится о проверке целостности информации в поле данных пакета, что заставляет отнести его к протоколам ненадежной доставки. Целостность данных проверяется протоколами транспортного уровня (TCP) или протоколами приложений.
Таким образом, вся информация о пути, по которому должен пройти пакет берется из самой сети в момент прохождения пакета. Именно эта процедура и называется маршрутизацией в отличии от коммутации, которая используется для предварительного установления маршрута следования данных, по которому потом эти данные отправляют.
Принцип маршрутизации является одним из тех факторов, который обеспечил гибкость сети Internet и ее победу в соревновании с другими сетевыми технологиями. Надо сказать, что маршрутизация является довольно ресурсоемкой процедурой, так как требует анализа каждого пакета, который проходит через шлюз или маршрутизатор, в то время как при коммутации анализируется только управляющая информация, устанавливается канал, физический или виртуальный, и все пакеты пересылаются по этому каналу без анализа маршрутной информации. Однако, эта слабость IP одновременно является и его силой. При неустойчивой работе сети пакеты могут пересылаться по различным маршрутам и затем собираться в единое сообщение. При коммутации путь придется каждый раз вычислять заново для каждого пакета, а в этом случае коммутация потребует больше накладных затрат, чем маршрутизация.
Вообще говоря, версий протокола IP существует несколько. В настоящее время используется версия Ipv4 (RFC791). Формат пакета протокола представлена на рисунке 2.8.

2.8. Формат пакета Ipv4
Фактически, в этом заголовке определены все основные данные, необходимые для перечисленных выше функций протокола IP: адрес отправителя (4-ое слово заголовка), адрес получателя (5-ое слово заголовка), общая длина пакета (поле Total Lenght) и тип пересылаемой датаграммы (поле Protocol).
Используя данные заголовка, машина может определить на какой сетевой интерфейс отправлять пакет. Если IP-адрес получателя принадлежит одной из ее сетей, то на интерфейс этой сети пакет и будет отправлен, в противном случае пакет отправят на другой шлюз (см. раздел 2.6).
Если пакет слишком долго "бродит" по сети, то очередной шлюз может отправить ICMP-пакет на машину-отправитель для того, чтобы уведомить о том, что надо использовать другой шлюз. При этом, сам IP-пакет будет уничтожен. На этом принципе работает программа ping, которая используется для деления маршрутов прохождения пакетов по сети.
Зная протокол транспортного уровня, IP-модуль производит раскапсулирование информации из своего пакета и ее направление на модуль обслуживания соответствующего транспорта.
При обсуждении формата заголовка пакета IP вернемся еще раз к инкапсулированию. Как уже отмечалось, при обычной процедуре инкапсулирования пакет просто помещается в поле данных фрейма, а в случае, когда это не может быть осуществлено, то разбивается на более мелкие фрагменты. Размер максимально возможного фрейма, который передается по сети, определяется величиной MTU (Maximum Transsion Unit), определенной для протокола канального уровня. Для того, чтобы потом восстановить пакет IP должен держать информацию о своем разбиении. Для этой цели используется поля "flags" и "fragmentation offset". В этих полях определяется, какая часть пакета получена в данном фрейме, если этот пакет был фрагментирован на более мелкие части.
Обсуждая протокол IP и вообще все семейство протоколов TCP/IP нельзя не упомянуть, что в настоящее время перед Internet возникло множество по-настоящему сложных проблем, которые требуют изменения базового протокола сети.
Протокол SLIP
(Serial Line Internet Protocol). Технология TCP/IP позволяет организовать межсетевое взаимодействие, используя различные физические и канальные протоколы обмена данными (IEEE 802.3 - ethernet, IEEE 802.5 - token ring, X.25 и т.п.). Однако, без обмена данными по телефонным линиям связи с использованием обычных модемов популярность Internet была бы значительно ниже. Большинство пользователей Сети используют свой домашний телефон в качестве окна в мир компьютерных сетей, подключая компьютер через модем к модемному пулу компании, предоставляющей IP-услуги или к своему рабочему компьютеру. Наиболее простым способом, обеспечивающим полный IP-сервис, является подключение через последовательный порт персонального компьютера по протоколу SLIP.
Согласно RFC-1055, впервые SLIP был включен в качестве средства доступа к IP-сети в пакет фирмы 3COM - UNET. В 1984 году Рик Адамс(Rick Adams) реализовал SLIP для BSD 4.2, и таким образом SLIP стал достоянием всего IP-сообщества.
Обычно, этот протокол применяют как на выделенных, так и на коммутируемых линиях связи со скоростями от 1200 до 19200 бит в секунду. Если модемы позволяют больше, то скорость можно "поднять", т.к. современные персональные компьютеры позволяют передавать данные в порт со скоростью 115200 битов за секунду. Однако, при определении скорости обмена данными следует принимать во внимание, что при передаче данных по физической линии данные подвергаются преобразованиям: компрессия и защита от ошибок на линии. Такое преобразование заставляет определять меньшую скорость на линии, чем скорость порта.
Следует отметить, что среди условно-свободно распространяемых программных IP-стеков (FreeWare), Trumpet Winsock, например, обязательно включена поддержка SLIP-коммуникаций. Такие операционные системы, как FreeBSD, Linux, NetBSD, которые можно свободно скопировать и установить на своем персональном компьютере, или HP-UX, которая поставляется вместе с рабочими станциями Hewlett Packard, имеют в своем арсенале программные средства типа sliplogin (FreeBSD) или slp (HP-UX), обеспечивающими работу компьютера в качестве SLIP-сервера для удаленных пользователей, подключающихся к IP-сети по телефону. В протоколе SLIP нет определения понятия "SLIP-сервер", но реальная жизнь вносит коррективы в стандарты. В контексте нашего изложения "SLIP-клиент" - это компьютер инициирующий физическое соединение, а "SLIP-сервер" - это машина, постоянно включенная в IP-сеть. В главе, посвященной организации IP-сетей и подключению удаленных компьютеров, будет подробно рассказано о различных способах подключения по SLIP-протоколу, поэтому не останавливаясь на деталях такого подключения перейдем к обсуждению самого протокола SLIP.
В отличии от Ethernet, SLIP не "заворачивает" IP-пакет в свою обертку, а "нарезает" его на "кусочки". При этом делает это довольно примитивно. SLIP-пакет начинается символом ESC (восьмеричное 333 или десятичное 219) и кончается символом END (восьмеричное 300 или десятичное 192). Если внутри пакета встречаются эти символы, то они заменяются двухбайтовыми последовательностями ESC-END (333 334) и ESC-ESC (333 335). Стандарт не определяет размер SLIP-пакета, поэтому любой SLIP-интерфейс имеет специальное поле, в котором пользователь должен указать эту длину. Однако, в стандарте есть указание на то, что BSD SLIP драйвер поддерживает пакеты длиной 1006 байт, поэтому "современные" реализации SLIP-программ должны поддерживать эту длину пакетов. SLIP-модуль не анализирует поток данных и не выделяет какую-либо информацию в этом потоке. Он просто "нарезает" ее на "кусочки", каждый из которых начинается символом ESC, а кончается символом END. Из приведенного выше описания понятно, что SLIP не позволяет выполнять какие-либо действия, связанные с адресами, т.к. в структуре пакета не предусмотрено поле адреса и его специальная обработка. Компьютеры, взаимодействующие по SLIP, обязаны знать свои IP-адреса заранее. SLIP не позволяет различать пакеты по типу протокола, например, IP или DECnet. Вообще-то, при работе по SLIP предполагается использование только IP (Serial Line IP все-таки), но простота пакета может быть соблазнительной и для других протоколов. В SLIP нет информации, позволяющей корректировать ошибки линии связи. Коррекция ошибок возлагается на протоколы транспортного уровня - TCP, UDP. В стандартном SLIP не предусмотрена компрессия данных, но существуют варианты протокола с такой компрессией. По поводу компрессии следует заметить следующее: большинство современных модемов, поддерживающих стандарты V.42bis и MNP5, осуществляют аппаратную компрессию. При этом практика работы по нашим обычным телефонным каналам показывает, что лучше отказаться от этой компрессии и работать только с автоматической коррекцией ошибок, например MNP4 или V.42. Вообще говоря, каждый должен подобрать тот режим, который наиболее устойчив в конкретных условиях работы телефонной сети (вплоть до времени года, и частоты аварий на теплотрассах).
Протокол UDP
- это один из двух протоколов транспортного уровня, которые используются в стеке протоколов TCP/IP. UDP позволяет прикладной программе передавать свои сообщения по сети с минимальными издержками, связанными с преобразованием протоколов уровня приложения в протокол IP. Однако при этом, прикладная программа сама должна заботиться о подтверждении того, что сообщение доставлено по месту назначения. Заголовок UDP-датаграммы (сообщения) имеет вид, показанный на рисунке 2.10.
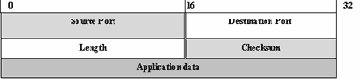
Рис. 2.10. Структура заголовка UDP-сообщения
Порты в заголовке определяют протокол UDP как мультиплексор, который позволяет собирать сообщения от приложений и отправлять их на уровень протоколов. При этом приложение использует определенный порт. Взаимодействующие через сеть приложения могут использовать разные порты, что и отражает заголовок пакета. Всего можно определить 216 разных портов. Первые 256 портов закреплены за, так называемыми "well known services", к которым относятся, например, 53 порт UDP, который закреплен за сервисом DNS.
Поле Length определяет общую длину сообщения. Поле Checksum служит для контроля целостности данных. Приложение, которое использует протокол UDP должно само заботится о целостности данных, анализируя поля Checksum и Length. Кроме этого, при обмене данными по UDP прикладная программа сама должна заботится о контроле доставки данных адресату. Обычно это достигается за счет обмена подтверждениями о доставке между прикладными программами.
Наиболее известными сервисами, основанными на UDP, является служба доменных имен BIND и распределенная файловая система NFS. Если возвратиться к примеру traceroute, то в этой программе также используется транспорт UDP. Собственно, именно сообщение UDP и засылается в сеть, но при этом используется такой порт, который не имеет обслуживания, поэтому и порождается ICMP-пакет, который и детектирует отсутствие сервиса на принимающей машине, когда пакет наконец достигает машину-адресата.
Протоколы SLIP и PPP
Интерес к этим двум протоколам вызван тем, что они применяются как на коммутируемых, так и на выделенных телефонных каналах. При помощи этих каналов к сети подключается большинство индивидуальных пользователей, а также небольшие локальные сети. Такие линии связи могут обеспечивать скорость передачи данных до 115200 битов за секунду.
Redirect routing
- это сообщение посылается в том случае, если шлюз не может доставить пакет, но у него есть на этот счет некоторые соображения, а именно адрес другого шлюза.
Slattach
:
/usr/paul/slattach /dev/cuaa0 144.206.160.100 144.206.160.101
Однако, формат slattach от одной системы к другой существенно изменяется. Так в ряде случаев сначала выдается команда slattach, которая присоединяет интерфейс к порту, а затем на нее выдается команда ifconfig для интерфейса sl.
/usr/paul>slattach -c -s 38400 /dev/sio01
/usr/paul>ifconfig sl1 inet 144.206.160.100 144.206.160.101 netmask 255.255.224.0
В данном случае определен интерфейс для обмена данными по протоколу SLIP с компрессией, со скоростью на порту 38400, через порт /dev/sio01.
Как показывает практика, доступ по протоколу SLIP обычно организуют для удаленных пользователей, которые через данный шлюз хотят работать с Internet. Однако, не всегда можно "зацепиться" за модем надежно. Кроме того, на одном и том же порту могут обслуживаться как терминальные пользователи, так и пользователи Internet, а кроме того, туда же можно подключать и пользователей UUCP. В этом случае гораздо разумнее вместо slattach воспользоваться командой
Sliplogin
. Данная команда также имеется не во всех операционных системах. Но обычно во всех есть ее аналог.
Суть sliplogin заключается в том, что пользователь, который дозвонился и работает в режиме удаленного терминала, имеет возможность самостоятельно запустить из этого режима присоединение sl интерфейса и его настройку на IP-адреса и параметры сессии. Это же дает возможность провайдерам, устанавливая стеки TCP/IP на персональных компьютерах, включать в их настройки скрипты, которые автоматически производят аутентификацию в удаленной машине и конфигурирование интерфейса для работы по SLIP.
Выглядит это следующим образом:
сначала дозваниваются до удаленной машины; затем вводят идентификатор и пароль; после входа в режим командной строки запускается команда sliplogin; после этого следует перейти в режим работы по SLIP.
Из этого режима обычно самостоятельно не выходят: либо обрывается связь, либо происходит какое-нибудь другое чрезвычайное событие. Поэтому систему настраивают таким образом, чтобы она сама завершала задачу и клала трубку на модеме.
Sliplogin управляется тремя файлами slip.hosts, slip.login и slip.logout. В файле slipl.host перечисляются пользователи, которым разрешено запускать sliplogin, и какие адреса при этом назначаются, а также тип протокола SLIP (с компрессией или без нее). Ниже приведен пример такого файла:
quest:/etc:\[7\]>cat slip.hosts paul 144.206.192.99 144.206.192.100 255.255.224.0 ; alex 144.206.130.138 144.206.192.102 255.255.224.0 compress dimag 144.206.192.99 144.206.192.103 255.255.224.0 dima 144.206.192.99 144.206.192.104 255.255.224.0 vovka 144.206.192.99 144.206.192.105 255.255.224.0 maverick 144.206.192.99 144.206.192.106 255.255.224 0 arch1996 144.206.192.99 144.206.192.107 255.255.224.0
Однако, этого мало. Фактически, sliplogin выполняет slattach на порт, через который работает пользователь, но после этого этот порт надо сконфигурировать. Для этой цели служит скрипт slip.login:
quest:/etc:\[8\]>cat slip.login #!/bin/sh /sbin/ifconfig sl$1 $4 $5 netmask $6 >> /tmp/sliplogin.log exit 0 quest:/etc:\[9\]>
После того, как соединение разорвалось, следует убрать все процессы которые им были вызваны. Для этой цели служит скрипт sliplogout.
quest:/etc:\[9\]>cat slip.logout #!/bin/sh PATH=:/bin:/sbin:/usr/bin:/usr/sbin: export PATH (ps ax | egrep 'sliplogin | slattach' | grep $3 |grep -v grep | awk '{print $1;}' | xargs kill ) >> /tmp/sliplogin.log quest:/etc:\[10\]>
Смысл написанного в этом файле заключается в том, что бы найти все остатки от sliplogin и по команде kill прервать их выполнение.
Однако для выделенных телефонных каналов обычно применяется другой протокол, а именно PPP.
Соединения типа "точка-точка" - протокол PPP (Point to Point Protocol)
. PPP - это более молодой протокол, нежели SLIP. Однако, назначение у него то же самое - управление передачей данных по выделенным или коммутируемым линиям связи. Согласно RFC-1661, PPP обеспечивает стандартный метод взаимодействия двух узлов сети. Предполагается, что обеспечивается двунаправленная одновременная передача данных. Как и в SLIP, данные "нарезаются" на фрагменты, которые называются пакетами. Пакеты передаются от узла к узлу упорядоченно. В отличии от SLIP, PPP позволяет одновременно передавать по линии связи пакеты различных протоколов. Кроме того, PPP предполагает процесс автоконфигурации обоих взаимодействующих сторон. Собственно говоря, PPP состоит из трех частей: механизма инкапсуляции (encapsulation), протокола управления соединением (link control protocol) и семейства протоколов управления сетью (network control protocols).
При обсуждении способов транспортировки данных при межсетевом обмене часто применяется инкапсуляция, например, инкапсуляция IP в X.25. С инкапсуляцией TCP в IP мы уже встречались. Инкапсуляция обеспечивает мультиплексирование различных сетевых протоколов (протоколов межсетевого обмена, например IP) через один канал передачи данных. Инкапсуляция PPP устроенна достаточно эффективно, например для передачи HDLC фрейма требуется всего 8 дополнительных байтов (8 октетов, согласно терминологии PPP). При других способах разбиения информации на фреймы число дополнительных байтов может быть сведено до 4 или даже 2. Для обеспечения быстрой обработки информации граница PPP пакета должна быть кратна 32 битам. При необходимости в конец пакета для выравнивания на 32-битовую границу добавляется "балласт". Вообще говоря, понятие инкапсуляции в терминах PPP - это не только добавление служебной информации к транспортируемой информации, но, если это необходимо, и разбиение этой информации на более мелкие фрагменты.
Под датаграммой в PPP понимают информационную единицу сетевого уровня, применительно к IP - IP-пакет. Под фреймом понимают информационную единицу канального уровня (согласно модели OSI). Фрейм состоит из заголовка и хвоста, между которыми содержатся данные. Датаграмма может быть инкапсулирована в один или несколько фреймов. Пакетом называют информационную единицу обмена между модулями сетевого и канального уровня. Обычно, каждому пакету ставится в соответствие один фрейм, за исключением тех случаев, когда канальный уровень требует еще большей фрагментации данных или, наоборот, объединяет пакеты для более эффективной передачи. Типичным случаем фрагментации являются сети ATM. В упрощенном виде PPP-фрейм показан на рисунке 2.7.

Рис. 2.7. PPP-фрейм
В поле "протокол" указывается тип инкапсулированной датаграммы. Существуют специальные правила кодирования протоколов в этом поле (см.ISO 3309 и RFC-1661). В поле "информация" записывается собственно пакет данных, а в поле "хвост" добавляется "пустышка" для выравнивания на 32-битувую границу. По умолчанию для фрейма PPP используется 1500 байтов. В это число не входит поле "протокол".
Протокол управления соединением предназначен для установки соглашения между узлами сети о параметрах инкапсуляции (размер фрейма, например). Кроме этого, протокол позволяет проводить идентификацию узлов. Первой фазой установки соединения является проверка готовности физического уровня передачи данных. При этом, такая проверка может осуществляться периодически, позволяя реализовать механизм автоматического восстановления физического соединения как это бывает при работе через модем по коммутируемой линии. Если физическое соединение установлено, то узлы начинают обмен пакетами протокола управления соединением, настраивая параметры сессии. Любой пакет, отличный от пакета протокола управления соединением, не обрабатывается во время этого обмена. После установки параметров соединения возможен переход к идентификации. Идентификация не является обязательной. После всех этих действий происходит настройка параметров работы с протоколами межсетевого обмена (IP, IPX и т.п.). Для каждого из них используется свой протокол управления. Для завершения работы по протоколу PPP по сети передается пакет завершения работы протокола управления соединением.
Процедура конфигурации сетевых модулей операционной системы для работы по протоколу PPP более сложное занятие, чем аналогичная процедура для протокола SLIP. Однако, возможности PPP соединения гораздо более широкие. Так например, при работе через модем модуль PPP, обычно, сам восстанавливает соединение при потере несущей частоты. Кроме того, модуль PPP сам определяет параметры своих фреймов, в то время как при SLIP их надо подбирать вручную. Правда, если настраивать оба конца, то многие проблемы не возникают из-за того, что параметры соединения известны заранее. Более подробно с протоколом PPP можно познакомиться в RFC-1661 и RFC-1548.
Статическая маршрутизация
В принципе, возможна работа без применения вообще каких-либо протоколов маршрутизации. В этом случае маршрутизацию называют статической. Таблица маршрутов в этом случае строится при помощи команд ifconfig, которые вписывают строки, отвечающие за рассылку сообщений в локальной сети, и команды route, которая используется для внесения изменений вручную.
Вообще говоря, из всей статической маршрутизации выделяют, так называемую, минимальную маршрутизацию. Такая маршрутизация возникает тогда, когда локальная сеть не имеет выхода в Internet и не состоит из подсетей. В этом случае достаточно выполнить команды ifconfig для интерфейса lo и интерфейса Ethernet и все будет работать:
/usr/paul>ifconfig lo inet 127.0.0.1 /usr/paul>ifconfig ed1 inet 144.226.43.1 netmask 255.255.255.0
В таблице маршрутов появятся только эти две строки, но так как сеть ограничена, и пакеты не надо отправлять в другие сети, то модуль ARP будет прекрасно справляться с доставкой пакетов по сети.
Если же сеть подключена к Internet, то в таблицу маршрутов надо ввести, по крайней мере, еще одну строку - адрес шлюза. Делается это при помощи команды route.
Команда route имеет следующий вид:
route <команда> <сеть или хост> <шлюз> <метрика>
В поле "команда" указывается команда работы с таблицей маршрутов:
add - добавить маршрут delete - удалить маршрут; get - получить информацию о маршруте.
В поле "сеть или хост" указывается адрес отправки пакета.
В поле "шлюз" указывается IP-адрес, через который следует отправлять пакеты, предназначенные хосту или сети из предыдущего поля.
Поле "метрика" определяет расстояние в числе шлюзов, которые данный пакет пройдет, если его направить по данному маршруту.
Типичным примером применения команды route является назначение шлюза по умолчанию:
/usr/paul>route add default 144.206.160.32
В данном примере все пакеты, адресаты которых не были найдены в локальной сети, отправляются на сетевой интерфейс с адресом 144.206.160.32. Метрика при этом принимается по умолчанию равная 1. Таким образом указывается, что это адрес шлюза.
Для того, чтобы получить таблицу маршрутов, приведенную в примере 2.1, нужно выполнить следующие команды:
/usr/paul>route add 144.206.0.0 144.206.136.5 netmask 255.255.224.0 /usr/paul>route add 144.206.96.0 144.206.130.135 netmask 255.255.224.0 /usr/paul>route add 144.206.128 144.206.130.138 netmask 255.255.224.0 /usr/paul>route add 144.206.192.0 144.206.192.1 netmask 255.255.224.0
Если сравнить эти записи с примером 2.1, то можно заметить, что одной строчки в списке команд не хватает. Это строка, которая описывает маршрут к сети 194.226.56 через шлюз 144.206.130.207. Дело в том, что поле флагов отчета netstat говорит нам, что такого маршрута в первоначальной таблице не было.
В поле флагов отчета netstat мы можем встретить следующие флаги:
U - говорит о том, что маршрут активен и может использоваться для маршрутизации пакетов;
H - говорит о том, что этот маршрут используется для посылки пакетов определенному в маршруте хосту;
G - говорит о том, что пакеты направляются на шлюз, который ведет к адресату;
D - этот флаг определяет тот факт, что данный маршрут был добавлен в таблицу по той причине, что с одного из шлюзов пришел ICMP-пакет, указывающий адрес правильного шлюза, который в нашей таблице отсутствовал.
Строчка, которая описывает не указанный в командах маршрут в таблице маршрутов выглядит следующим образом:
Destination Gateway Flags Refs Use IfaceMTU Rtt 194.226.56 144.206.130.207 UGD 0 0 ed1 - -
Поле флагов содержит флаги: U-маршрут активен, G-пакеты направляются на шлюз и D-маршрут получен по сообщению ICMP о перенаправлении пакетов. Следовательно, первоначально такого маршрута в таблице маршрутов не было.
Если пользователи системы часто ходят в сеть 194.226.56.0, то в таблицу такой маршрут следует добавить:
/usr/paul>route add 194.226.56.0 144.206.130.207 netmask 255.255.224.0
При помощи команды route можно не только добавлять маршруты в таблицу маршрутов, но и удалять их от туда. Делается это по команде
Структура стека протоколов TCP/IP
При рассмотрении процедур межсетевого взаимодействия всегда опираются на стандарты, разработанные International Standard Organization (ISO). Эти стандарты получили название "Семиуровневой модели сетевого обмена" или в английском варианте "Open System Interconnection Reference Model" (OSI Ref.Model). В данной модели обмен информацией может быть представлен в виде стека, представленного на рисунке 2.1. Как видно из рисунка, в этой модели определяется все - от стандарта физического соединения сетей до протоколов обмена прикладного программного обеспечения. Дадим некоторые комментарии к этой модели.
Физический уровень данной модели определяет характеристики физической сети передачи данных, которая используется для межсетевого обмена. Это такие параметры, как: напряжение в сети, сила тока, число контактов на разъемах и т.п. Типичными стандартами этого уровня являются, например RS232C, V35, IEEE 802.3 и т.п.

Рис. 2.1. Семиуровневая модель протоколов межсетевого обмена OSI
и Производители, за которыми эти
Префиксы адресов Ethernet интерфейсов(карт) и Производители, за которыми эти префиксы закреплены
| Префикс | Производитель | Префикс | Производитель |
| 00:00:0C | Cisco | 08:00:0B | Unisys |
| 00:00:0F | NeXT | 08:00:10 | T&T |
| 00:00:10 | Sytek8:00:11 | Tektronix | |
| 00:00:1D | Cabletron | 08:00:14 | Exelan |
| 00:00:65 | Network General | 08:00:1A | Data General |
| 00:00:6B | MIPS | 08:00:1B | Data General |
| 00:00:77 | Cayman System | 08:00:1E | Sun |
| 00:00:93 | Proteon | 08:00:20 | CDC |
| 00:00:A2 | Wellfleet | 08:00:2% | DEC |
| 00:00:A7 | NCD | 08:00:2B | Bull |
| 00:00:A9 | Network Systems | 08:00:38 | Spider Systems |
| 00:00:C0 | Western Digital | 08:00:46 | Sony |
| 00:00:C9 | Emulex | 08:00:47 | Sequent |
| 00:80:2D | Xylogics Annex | 08:00:5A | IBM |
| 00:AA:00 | Intel | 08:00:69 | Silicon Graphics |
| 00:DD:00 | Ungermann-Bass | 08:00:6E | Exelan |
| 00:DD:01 | Ungermann-Bass | 08:00:86 | Imageon/QMS |
| 02:07:01 | MICOM/Interlan | 08:00:87 | Xyplex terminal servers |
| 02:60:8C | 3Com | 08:00:89 | Kinetics |
| 08:00:02 | 3Com(Bridge) | 08:00:8B | Pyromid |
| 08:00:03 | ACC | 08:00:90 | Retix |
| 08:00:05 | Symbolics | AA:00:03 | DEC |
| 08:00:08 | BBN | AA:00:04 | DEC |
| 08:00:09 | Hewlett-Packard |
Технология Ethernet
. Кадр Ethernet содержит адрес назначения, адрес источника, поле типа и данные. Размер адреса Ethernet - 6 байтов. Каждый сетевой адаптер имеет свой сетевой адрес. Адаптер "слушает" сеть, принимает адресованные ему кадры и широковещательные кадры с адресом FF:FF:FF:FF:FF:FF, отправляет кадры в сеть.
Технология Ethernet реализует метод множественного доступа с контролем несущей и обнаружением столкновений. Этот метод предполагает, что все устройства взаимодействуют в одной среде. В каждый момент времени передавать может только одно устройство, а все остальные только слушать. Если два или более устройств пытаются передать кадр одновременно, то фиксируется столкновение и каждое устройство возобновляет попытку передачи кадра через случайный промежуток времени. Одним словом, в каждый момент времени в сегменте узла сети находится только один кадр.
Понятно, что чем больше компьютеров подключено в сегменте Ethernet, тем больше столкновений будет зафиксировано и тем медленнее будет работать сеть. Кроме того, если в сети стоит сервер, к которому часто обращаются, то это также снизит общую производительность сети.
Важной особенностью интерфейса Ethernet является то, что каждая интерфейсная карта имеет свой уникальный адрес. Каждому производителю карт выделен свой пул адресов в рамках которого он может выпускать карты (таблица 2.1). Согласно протоколу Ethernet, каждый интерфейс имеет 6-ти байтовый адрес. Адрес записывается в виде шести групп шестнадцатиричных цифр по две в каждой (шестнадцатеричная записи байта). Первые три байта называются префиксом, и именно они закреплены за производителем. Каждый префикс определяет 224 различных комбинаций, что равно почти 17-ти млн. адресам.
Transfer Control Protocol - TCP
Если для приложения контроль качества передачи данных по сети имеет значение, то в этом случае используется протокол TCP. Этот протокол еще называют надежным, ориентированным на соединение и потокоориентированным протоколом. Прежде чем обсудить эти свойства протокола, рассмотрим формат передаваемой по сети датаграммы (рисунок 2.11). Согласно этой структуре, в TCP, как и в UDP, имеются порты. Первые 256 портов закреплены за WKS, порты от 256 до 1024 закреплены за Unix-сервисами, а остальные можно использовать по своему усмотрению. В поле Sequence Number определен номер пакета в последовательности пакетов, которая составляет все сообщение, за тем идет поле подтверждения Asknowledgment Number и другая управляющая информация.
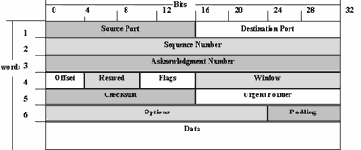
Рис. 2.11. Структура пакета TCP
Надежность TCP заключается в том, что источник данных повторяет их посылку, если только не получит в определенный промежуток времени от адресата подтверждение об их успешном получении. Этот механизм называется Positive Asknowledgement with Retransmission (PAR). Как мы ранее определили, единица пересылки (пакет данных, сообщение и т.п.) в терминах TCP носит название сегмента. В заголовке TCP существует поле контррольной суммы. Если при пересылке данные повреждены, то по контрольной сумме модуль, вычленяющий TCP-сегменты из пакетов IP, может определить это. Поврежденный пакет уничтожается, а источнику ничего не посылается. Если данные не были повреждены, то они пропускаются на сборку сообщения приложения, а источнику отправляется подтверждение.
Ориентация на соединение определяется тем, что прежде чем отправить сегмент с данными, модули TCP источника и получателя обмениваются управляющей информацией. Такой обмен называется
Транспортный
уровень отвечает за надежность доставки данных, и здесь, проверяя контрольные суммы, принимается решение о сборке сообщения в одно целое. В Internet транспортный уровень представлен двумя протоколами TCP (Transport Control Protocol) и UDP (User Datagramm Protocol). Если предыдущий уровень (сетевой) определяет только правила доставки информации, то транспортный уровень отвечает за целостность доставляемых данных.
Уровень обмена данными с прикладными программами
(Presentation Layer) необходим для преобразования данных из промежуточного формата сессии в формат данных приложения. В Internet это преобразование возложено на прикладные программы.
Уровень прикладных программ или приложений
определяет протоколы обмена данными этих прикладных программ. В Internet к этому уровню могут быть отнесены такие протоколы, как: FTP, TELNET, HTTP, GOPHER и т.п.
Вообще говоря, стек протоколов TCP отличается от только что рассмотренного стека модели OSI. Обычно его можно представить в виде схемы, представленной на рисунке 2.2.

Рис. 2.2. Структура стека протоколов TCP/IP
В этой схеме на уровне доступа к сети располагаются все протоколы доступа к физическим устройствам. Выше располагаются протоколы межсетевого обмена IP, ARP, ICMP. Еще выше основные транспортные протоколы TCP и UDP, которые кроме сбора пакетов в сообщения еще и определяют какому приложению необходимо данные отправить или от какого приложения необходимо данные принять. Над транспортным уровнем располагаются протоколы прикладного уровня, которые используются приложениями для обмена данными.
Базируясь на классификации OSI (Open System Integration) всю архитектуру протоколов семейства TCP/IP попробуем сопоставить с эталонной моделью (рисунок 2.3).
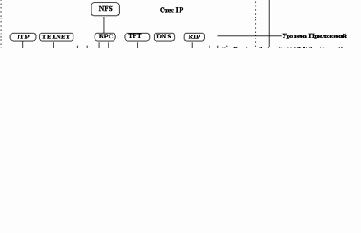
Рис. 2.3. Схема модулей, реализующих протоколы семейства TCP/IP в узле сети
Прямоугольниками на схеме обозначены модули, обрабатывающие пакеты, линиями - пути передачи данных. Прежде чем обсуждать эту схему, введем необходимую для этого терминологию.
Драйвер - программа, непосредственно взаимодействующая с сетевым адаптером.
Модуль - это программа, взаимодействующая с драйвером, с сетевыми прикладными программами или с другими модулями.
Схема приведена для случая подключения узла сети через локальную сеть Ethernet, поэтому названия блоков данных будут отражать эту специфику.
Сетевой интерфейс - физическое устройство, подключающее компьютер к сети. В нашем случае - карта Ethernet.
Кадр - это блок данных, который принимает/отправляет сетевой интерфейс.
IP-пакет - это блок данных, которым обменивается модуль IP с сетевым интерфейсом.
UDP-датаграмма - блок данных, которым обменивается модуль IP с модулем UDP.
TCP-сегмент - блок данных, которым обменивается модуль IP с модулем TCP.
Прикладное сообщение - блок данных, которым обмениваются программы сетевых приложений с протоколами транспортного уровня.
Инкапсуляция - способ упаковки данных в формате одного протокола в формат другого протокола. Например, упаковка IP-пакета в кадр Ethernet или TCP-сегмента в IP-пакет. Согласно словарю иностранных слов термин "инкапсуляция" означает "образование капсулы вокруг чужих для организма веществ (инородных тел, паразитов и т.д.)". В рамках межсетевого обмена понятие инкапсуляции имеет несколько более расширенный смысл. Если в случае инкапсуляции IP в Ethernet речь идет действительно о помещении пакета IP в качестве данных Ethernet-фрейма, или, в случае инкапсуляции TCP в IP, помещение TCP-сегмента в качестве данных в IP-пакет, то при передаче данных по коммутируемым каналам происходит дальнейшая "нарезка" пакетов теперь уже на пакеты SLIP или фреймы PPP.
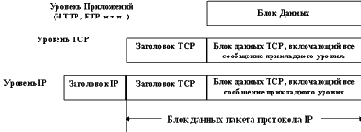
Рис. 2.4. Инкапсуляция протоколов верхнего уровня в протоколы TCP/IP
Вся схема (рисунок 2.4) называется стеком протоколов TCP/IP или просто стеком TCP/IP. Чтобы не возвращаться к названиям протоколов расшифруем аббревиатуры TCP, UDP, ARP, SLIP, PPP, FTP, TELNET, RPC, TFTP, DNS, RIP, NFS:
TCP - Transmission Control Protocol - базовый транспортный протокол, давший название всему семейству протоколов TCP/IP.
UDP - User Datagram Protocol - второй транспортный протокол семейства TCP/IP. Различия между TCP и UDP будут обсуждены позже.
ARP - Address Resolution Protocol - протокол используется для определения соответствия IP-адресов и Ethernet-адресов.
SLIP - Serial Line Internet Protocol (Протокол передачи данных по телефонным линиям).
PPP - Point to Point Protocol (Протокол обмена данными "точка-точка").
FTP - File Transfer Protocol (Протокол обмена файлами).
TELNET - протокол эмуляции виртуального терминала.
RPC - Remote Process Control (Протокол управления удаленными процессами).
TFTP - Trivial File Transfer Protocol (Тривиальный протокол передачи файлов).
DNS - Domain Name System (Система доменных имен).
RIP - Routing Information Protocol (Протокол маршрутизации).
NFS - Network File System (Распределенная файловая система и система сетевой печати).
При работе с такими программами прикладного уровня, как FTP или telnet, образуется стек протоколов с использованием модуля TCP, представленный на рисунке 2.5.
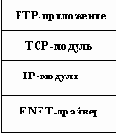
Рис. 2.5. Стек протоколов при использовании модуля TCP
При работе с прикладными программами, использующими транспортный протокол UDP, например, программные средства Network File System (NFS), используется другой стек, где вместо модуля TCP будет использоваться модуль UDP (рисунок 2.6).

Рис. 2.6. Стек протоколов при работе через транспортный протокол UDP
При обслуживании блочных потоков данных модули TCP, UDP и драйвер ENET работают как мультиплексоры, т.е. перенаправляют данные с одного входа на несколько выходов и наоборот, с многих входов на один выход. Так, драйвер ENET может направить кадр либо модулю IP, либо модулю ARP, в зависимости от значения поля "тип" в заголовке кадра. Модуль IP может направить IP-пакет либо модулю TCP, либо модулю UDP, что определяется полем "протокол" в заголовке пакета.
Получатель UDP-датаграммы или TCP-сообщения определяется на основании значения поля "порт" в заголовке датаграммы или сообщения.
Все указанные выше значения прописываются в заголовке сообщения модулями на отправляющем компьютере. Так как схема протоколов - это дерево, то к его корню ведет только один путь, при прохождении которого каждый модуль добавляет свои данные в заголовок блока. Машина, принявшая пакет, осуществляет демультиплексирование в соответствии с этими отметками.
Технология Internet поддерживает разные физические среды, из которых самой распространенной является Ethernet. В последнее время большой интерес вызывает подключение отдельных машин к сети через TCP-стек по коммутируемым (телефонным) каналам. С появлением новых магистральных технологий типа ATM или FrameRelay активно ведутся исследования по инкапсуляции TCP/IP в эти протоколы. На сегодняшний день многие проблемы решены и существует оборудование для организации TCP/IP сетей через эти системы.
Уровень сессии
определяет стандарты взаимодействия между собой прикладного программного обеспечения. Это может быть некоторый промежуточный стандарт данных или правила обработки информации. Условно к этому уровню можно отнеси механизм портов протоколов TCP и UDP и Berkeley Sockets. Однако обычно, рамках архитектуры TCP/IP такого подразделения не делают.
Внешние протоколы
служат для обмена информацией о маршрутах между автономными системами.
Внутренние протоколы
служат для обмена информацией о маршрутах внутри автономной системы.
В реальной практике построения локальных сетей, корпоративных сетей и их подключения к провайдерам нужно знать, главным образом, только внутренние протоколы динамической маршрутизации. Внешние протоколы динамической маршрутизации необходимы только тогда, когда следует построить закрытую большую систему, которая с внешним миром будет соединена только небольшим числом защищенных каналов данных.
К внешним протоколам относятся Exterior Gateway Protocol (EGP) и .
