Обмен файлами. Служба архивов FTP
FTP-архивы являются одним из основных информационных ресурсов Internet. Фактически, это распределенный депозитарий текстов, программ, фильмов, фотографий, аудио записей и прочей информации, хранящейся в виде файлов на различных компьютерах во всем мире.
Обращение к файлу базы данных
отличается от посещения страницы тем, что одна страница может состоять из нескольких файлов. В качестве простого примера можно указать на страницы с тагами <IMG>. В этом случае программа клиент порождает запрос не только к файлу с расширением html, но и к файлам, указанным в странице в качестве встроенных картинок с расширениями gif, например.
В настоящее время существует несколько типов журналов посещений. Формат журнала зависит от типа сервера, который используется для ведения базы данных. Однако, в настоящее время формат записей журнала посещений стабилизировался, и большинство серверов поддерживает следующий перечень полей:
Доменное имя удаленного хоста или его IP-адрес. Имя пользователя(часто не указывается и заменяется на символ "-") Идентификация пользователя( Заменяется на "-" если не используется запрос идентификации) Дата и время посещения Запрос клиента Код возврата Количество переданных байтов
Некоторые серверы в дополнение к этим полям записывают в журнал еще и URL страницы, с которой осуществлен доступ(если клиент не сообщает этой информации, то поле заменяется символом "-") Тип программного обеспечения клиента
Ниже приведен пример типичного журнала посещений, который ведется сервером NCSA, использующимся в системе "Полынь".
Общий набор правил преобразования адресов
, который не меняется от машины к машине и от конфигурации к конфигурации (Rule Set 0).
Опции командной строки
. Командная строка используется только при запросах типа ISIN-DEX. При HTML FORMS или любых других запросах неопределенного типа командная строка не используется. Если сервер определил, что к скрипту обращаются через ISINDEX-документ, то поисковый критерий выделяется из URL и преобразуется в параметры командной строки. При этом знаком разделения параметров является символ "+". Тип запроса определяется по наличию или отсутствию символа "=" в запросе. Если этот символ есть, то запрос не является запросом ISINDEX, если символа нет, то запрос принадлежит к типу ISIN-DEX. Параметры, выделенные из запроса, помещаются в массив параметров командной строки argv. При этом после из выделения происходит преобразование всех шестнадцатеричных символов в их ASCII-коды. Если число параметров превышает ограничения, установленные в командном языке, например в shell, то формирования командной строки не происходит и данные передаются только через QUERY_STRING. Вообще говоря, следует заранее подумать об объеме данных, передаваемом скрипту и выбрать соответствующий метод доступа. Размер переменных окружения тоже ограничен, и если необходимо передавать много данных, то лучше сразу выбрать метод POST, т.е. передачу данных через стандартный ввод.
Опции команды sendmail
. Опции определяют режимы работы программы. Опции можно задавать в виде параметров командной строки, а можно в виде описаний в файле настройки.
OpenText
Информационная система OpenText представляет из себя самый коммерциализированный информационный продукт в сети. Все описания больше напоминают рекламу, чем реальное руководство по работе. Система позволяет провести поиск с использованием логических коннекторов, размер запроса ограничен тремя терминами или фразами. В данном случае речь идет о расширенном поиске. При выдаче результатов поиска сообщается степень соответствия документа запросу и размер документа. Система позволяет также улучшить результаты поиска в стиле традиционного булевого поиска.
OpenText можно было бы отнести без сомнения к разряду традиционных информационно-поисковых систем, если бы не механизм ранжирования.
- документ занимает пятую строчку в списке из десяти документов. Как и в случае с InfoSeek уточнение запроса результатов не дало.
Описание формата заголовка почтового сообщения
. В данной секции определяются поля и их формат, которые отображаются в заголовке. Многие поля заголовка sendmail генерирует на основе информации из конверта почтового сообщения.
Описание классов
, т.е. групп имен, которые используются программой для рассылки почты. Например, для рассылки в другие почтовые службы.
Описание макроопределений sendmail
, отвечающих за работу в локальной сети, например имя домена и "официальное имя" машины.
Описание особенностей данной машины (local information)
- в данной секции описываются такие параметры, как имя данной машины, имя UUCP и т.п.
Описание программ рассылки
. В данной секции описываются имена программ рассылки, пути и параметры командной строки этих программ. Обычно это программа местной рассылки, рассылка по UUCP, рассылка по SMTP, рассылка на выполнение.
Определение порядка сообщений
программы sendmail (Precedence). Обычно эта секция не модифицируется администратором.
Организация информационной службы на основе технологии World Wide Web
В последнее время, активно прорабатываются различные варианты реализации информационной службы на основе серверов HTTP. Основу этой идеи составляет тот факт, что базовое программное обеспечение уже существует. Существует также и формат предоставления документов и спецификации взаимодействия с внешним, по отношению к серверу, программным обеспечением.
Перед такого рода системами ставится несколько задач:
представление информации об организации, сбор информации об информационных запросах пользователей, сбор информации об информационных нуждах сотрудников организации.
Первая задача решается путем создания стандартной базы данных Web и установкой сервера, который будет работать в стандартном режиме.
Вторая задача решается за счет анализа журналов посещения сервера пользователями Internet и путем организации интерфейсных страниц для сбора информации об этих пользователях.
Третья задача решается за счет анализа кэша сервера. Все запросы сотрудников захватываются в этот кэш и доступны для администрации сервера. Все это позволяет говорить о создании аналитической службы, главной задачей которой является анализ информационных потребностей различных ей информации в World Wide Web. Приведем некоторые примеры анализа этой статистики.
Организация модемных пулов, настройка оборудования. Квоты пользователей
При обсуждении вопроса о доступе в режиме удаленного терминала нельзя обойти возможность доступа к системе по телефону, с использованием модема. Это совершенно другая, отличная от telnet технология. При обсуждении вопросов доступа к Internet в режиме Dial-IP уже обсуждались вопросы связанные с тем, что базовым методом доступа для режима IP является режим удаленного терминала, когда пользователь получает удаленный терминал (физически удаленный, но работающий точно также, как и локальный). В этом случае пользователь получает доступ не на виртуальные терминалы типа /dev/ttypX, а к устройствам типа /dev/ttydX, которые обычно используются для подключения модемов.
При подключении модема к компьютеру следует настроить терминал для работы с модемом, т.е. создать устройство /dev/ttydX, установить скорость обмена между портом компьютера и модемом, "залочить" модем.
Для создания устройства можно использовать скрипт MAKEDEV или команду mknode. В разных системах это делается по разному. Так в SCO или HP-UX устройство можно создать из интерфейса системного администратора.
Сцепление порта и устройства осуществляется через файл, выполняющийся в момент начальной загрузки в системе FreeBSD, например это делается через файл /etc/ttys:
# @(#)ttys 5.1 (Berkeley) 4/17/89 # # name getty type status comments # # This entry needed for asking password when init goes to single-user mode # If you want to be asked for password, change "secure" to "insecure" here console none unknown off secure # ttyv0 "/usr/libexec/getty Pc" cons25 on secure # Virtual terminals ttyv1 "/usr/libexec/getty Pc" cons25 on secure ttyv2 "/usr/libexec/getty Pc" cons25 on secure ttyv3 "/usr/libexec/getty Pc" cons25 off secure # Serial terminals ttyd0 "/usr/libexec/getty std.38400" dialup on secure ttyd1 "/usr/libexec/getty std.9600" unknown off secure ttyd2 "/usr/libexec/getty std.9600" unknown off secure ttyd3 "/usr/libexec/getty std.9600" unknown off secure # Pseudo terminals ttyp0 none network ttyp1 none network ttyp2 none network ttyp3 none network
В данном случае строка соответствующая терминалу ttyd0, используется для подключения модема. При этом на порте установлена скорость 38400, что позволяет подключать высокоскоростные модемы. Сам тип терминала dial-in описан в фале termcap. Скорость на модеме устанавливается согласно описаниям из файла gettytypes. Однако все это справедливо для систем a la BSD системах System 5 файлы настроек будут другие.
"Залочить" модем это значит, что скорость передачи данных между модемом и портом постоянная и не зависит от скорости на линии. Обычно схему подключения модема к компьютеру представляют в следующем виде:

Рис. 3.21. Взаимодействие модема и последовательного порта
Скорость на линии, обычно, устанавливается согласно возможностям модема. Большинство модемов способны сами договариваться о скорости передачи данных. При этом, обычно используются протоколы коррекции ошибок и сжатие данных. Таким образом, модем занимается преобразованием данных, что естественно требует определенного времени. Если применяется компрессия, то в порт будет передаваться байтов больше, чем их передается по линии, следовательно скорость обмена данными между модемом и компьютером должна быть больше скорости обмена данными между модемами.
На схеме также изображено, так называемое "жесткое" управление соединением (Hardware Hadshaking), которое должно быть выбрано для управления модемом при его настройках. Принимающий вызовы модем должен быть сконфигурирован таким образом, чтобы он сам снимал трубку (ats0=5). Если кроме приема звонков от удаленных компьютеров телефон используется еще и как обычный телефон, то значение регистра s0 надо установить побольше.
Кроме того при работе с Unix следует принять во внимание тот факт, что некоторые системы работают с 7-битовыми терминалами. В этом случае при настройке программ пользователей в поле "Data Langth" следует указывать значение 7, а в поле Parity указывают Even.
Допуск пользователей к ресурсам системы в режиме удаленного терминала заставляет задуматься о квотировании ресурсов для каждого пользователя. Квотированию подлежат:
время использования процессора; размер используемого дискового пространства; время доступа к системе; каналы доступа к системе.
С точки зрения сетевого администрирования, все эти параметры подлежат если не ограничению, то строгому учету.
Время использования машины связано с тем, что при анализе активности пользователя может оказаться, что система используется третьим лицом, а не реальным пользователем для доступа к ресурсам сети. При этом программы подбора паролей "поедают" достаточно много времени процессора.
Размер используемого дискового пространства влияет на возможность пользователя получать и хранить информацию из сети, например по FTP, а также на размер принимаемых почтовых сообщений.
Время доступа к системе определяет возможность доступа пользователя по времени суток. Можно запретить работать с удаленных терминалов в рабочее время, когда телефон нужен для других целей.
Ограничение доступа к системе через виртуальные терминалы и удаленные терминалы должно служить повышению безопасности всей сети в целом.
Основные компоненты технологии World Wide Web
К 1989 году гипертекст представлял новую, многообещающую технологию, которая имела относительно большое число реализаций с одной стороны, а с другой стороны делались попытки построить формальные модели гипертекстовых систем, которые носили скорее описательный характер и были навеяны успехом реляционного подхода описания данных. Идея Т.Бернерс-Ли заключалась в том, чтобы применить гипертекстовую модель к информационным ресурсам, распределенным в сети, и сделать это максимально простым способом. Он заложил три краеугольных камня системы из четырех существующих ныне, разработав:
язык гипертекстовой разметки документов HTML (HyperText Markup Language); универсальный способ адресации ресурсов в сети URL (Universal Resource Locator); протокол обмена гипертекстовой информацией HTTP (HyperText Transfer Protocol).
Позже команда NCSA добавила к этим трем компонентам четвертый:
универсальный интерфейс шлюзов CGI (Common Gateway Interface).
Java не включается в этот список намеренно, т.к. область применения этого языка гораздо шире чем простое "оживление" World Wide Web.
Идея HTML - пример чрезвычайно удачного решения проблемы построения гипертекстовой системы при помощи специального средства управления отображением. На разработку языка гипертекстовой разметки существенное влияние оказали два фактора: исследования в области интерфейсов гипертекстовых систем и желание обеспечить простой и быстрый способ создания гипертекстовой базы данных, распределенной на сети.
В 1989 году активно обсуждалась проблема интерфейса гипертекстовых систем, т.е. способов отображения гипертекстовой информации и навигации в гипертекстовой сети. Значение гипертекстовой технологии сравнивали со значением книгопечатания. Утверждалось, что лист бумаги и компьютерные средства отображния/воспроизведения серьезно отличаются друг от друга, и поэтому форма представления информации тоже должна отличаться. Наиболее эффективной формой организации гипертекста были признаны контекстные гипертекстовые ссылки, а кроме того, было признано деление на ссылки, ассоциированные со всем документом в целом и отдельными его частями.
Самым простым способом создания любого документа является его набивка в текстовом редакторе. Опыт создания хорошо размеченных для последующего отображения документов в CERN'е был - трудно найти физика, который не пользовался бы системой TeX или LaTeX. Кроме того к тому времени существовал стандарт языка разметки - Standard Generalised Markup Language (SGML).
Следует также принять во внимание, что согласно своим предложениям Т.Бернерс-Ли предполагал объединить в единую систему имеющиеся информационные ресурсы CERN, и первыми демонстрационными системами должны были стать системы для NeXT и VAX/VMS.
Обычно гипертекстовые системы имеют специальные программные средства построения гипертекстовых связей. Сами гипертекстовые ссылки хранятся в специальных форматах или даже составляют специальные файлы. Такой подход хорош для локальной системы, но не для распределенной на множестве различных компьютерных платформ. В HTML гипертекстовые ссылки встроены в тело документа и хранятся как его часть. Часто в системах применяют специальные форматы хранения данных для повышения эффективности доступа. В WWW документы - это обычные ASCII- файлы, которые можно подготовить в любом текстовом редакторе. Таким образом, проблема создания гипертекстовой базы данных была решена чрезвычайно просто.
В качестве базы для разработки языка гипертекстовой разметки был выбран SGML (Standard Generalised Markup Language). Следуя академическим традициям, Бернерс-Ли описал HTML в терминах SGML (как описывают язык программирования в терминах формы Бекуса-Наура). Естественно, что в HTML были реализованы все разметки, связанные с выделением параграфов, шрифтов, стилей и т.п., т.к. реализация для NeXT подразумевала графический интерфейс. Важным компонентом языка стало описание встроенных и ассоциированных гипертекстовых ссылок, встроенной графики и обеспечение возможности поиска по ключевым словам.
С момента разработки первой версии языка (HTML 1.0) прошло уже пять лет. За это время произошло довольно серьезное развитие языка. Почти вдвое увеличилось число элементов разметки, оформление документов все больше приближается оформлению качественных печатных изданий, развиваются средства описания нетекстовых информационных ресурсов и способы взаимодействия с прикладным программным обеспечением. Совершенствуется механизм разработки типовых стилей. Фактически, в настоящее время HTML развивается в сторону создания стандартного языка разработки интерфейсов как локальных, так и распределенных систем.
Вторым краеугольным камнем WWW стала универсальная форма адресации информационных ресурсов. Universal Resource Identification (URI) представляет собой довольно стройную систему, учитывающую опыт адресации и идентификации e-mail, Gopher, WAIS, telnet, ftp и т.п. Но реально из всего, что описано в URI, для организации баз данных в WWW требуется только Universal Resource Locator (URL). Без наличия этой спецификации вся мощь HTML оказалась бы бесполезной. URL используется в гипертекстовых ссылках и обеспечивает доступ к распределенным ресурсам сети. В URL можно адресовать как другие гипертекстовые документы формата HTML, так и ресурсы e-mail, telnet, ftp, Gopher, WAIS, например. Различные интерфейсные программы по-разному осуществляют доступ к этим ресурсам. Одни, как например Netscape, сами способны поддерживать взаимодействие по протоколам, отличным от протокола HTTP, базового для WWW, другие, как например Chimera, вызывают для этой цели внешние программы. Однако, даже в первом случае, базовой формой представления отображаемой информации является HTML, а ссылки на другие ресурсы имеют форму URL. Следует отметить, что программы обработки электронной почты в формате MIME также имеют возможность отображать документы, представленные в формате HTML. Для этой цели в MIME зарезервирован тип "text/html".
Третьим в нашем списке стоит протокол обмена данными в World Wide Web - HTTP (Hyper-Text Transfer Protocol). Данный протокол предназначен для обмена гипертекстовыми документами и учитывает специфику такого обмена. Так в процессе взаимодействия, клиент может получить новый адрес ресурса на сети (relocation), запросить встроенную графику, принять и передать параметры и т. п. Управление в HTTP реализовано в виде ASCII-команд. Реально, разработчик гипертекстовой базы данных сталкивается с элементами протокола только при использовании внешних расчетных программ или при доступе к внешним, относительно WWW, информационным ресурсам, например базам данных.
Последняя составляющая технологии WWW - это уже плод работы группы NCSA - спецификация CGI (Common Gateway Interface). CGI была специально разработана для расширения возможностей WWW за счет подключения всевозможного внешнего программного обеспечения. Такой подход логично продолжал принцип публичности и простоты разработки и наращивания возможностей WWW. Если команда CERN предложила простой и быстрый способ разработки баз данных, то NCSA развила этот принцип на разработку программных средств. Надо заметить, что в общедоступной библиотеке CERN были модули, позволяющие программистам подключать свои программы к серверу HTTP, но это требовало использования этой библиотеки. Предложенный и описанный в CGI способ подключения не требовал дополнительных библиотек и буквально ошеломлял своей простотой. Сервер взаимодействовал с программами через стандартные потоки ввода/вывода, что упрощает программирование до предела. При реализации CGI чрезвычайно важное место заняли методы доступа, описанные в HTTP. И хотя реально используются только два из них (GET и POST), опыт развития HTML показывает, что сообщество WWW ждет развития и CGI по мере усложнения задач, в которых будет использоваться WWW-технология.
Переменные окружения
. При запуске внешней программы сервер создает специфические переменные окружения, через которые передает приложению как служебную информацию, так и данные. Все переменные можно разделить на общие переменные окружения, которые генерируются при любой форме запроса, и запрос-ориентированные переменные.
К общим переменным окружения относятся:
SERVER_SOFTWARE - определяет имя и версию сервера. SERVER_NAME - определяет доменное имя сервера. GATEWAY_INTERFACE - определяет версию интерфейса.
К запрос-ориентированным относятся:
SERVER_PROTOCOL - протокол сервера. Вообще говоря, CGI разрабатывалась не только для применения в World Wide Web с протоколом HTTP, но и для других протоколов также, но широкое применение получила только в WWW. SERVER_PORT - определяет порт TCP, по которому осуществляется взаимодействие. По умолчанию для работы по HTTP используется 80 порт, но он может быть и переназначен при конфигурировании сервера. REQUEST_METHOD - определяет метод доступа к информационному ресурсу. Это важнейшая переменная в CGI. Разные методы доступа используют различные механизмы передачи данных. Данная переменная может принимать значения GET, POST, HEAD и т. п. PATH_INFO - передает программе путь, часть спецификации URL, в том виде, в котором она указана в клиентом. Реально это означает, что передается путь (адрес скрипта) в виде, указанном в HTML-документе. PATH_TRANSLATED - то же самое, что и PATH_INFO, но только после подстановки сервером определенных в его конфигурации вставок. Дело в том, что при конфигурировании сервера некоторым элементам (ветвям) дерева файловой системы можно назначить синонимы. Типичным примером такого сорта является назначение типа:
cgi-bin ------------> /usr/local/etc/httpd/cgi-bin
В данном случае справа указано стандартное место CGI скриптов для сервера NCSA, а слева - его синоним. При получении скриптом test управления, в переменной окружения PATH_INFO будет значение:
"/cgi-bin/test", а в PATH_TRANSLATED - "/usr/local/etc/httpd/cgi-bin/test".
SCRIPT_NAME - определяет адрес скрипта так, как он указан клиентом. Если не указаны параметры, то значение этой переменной будут совпадать с PATH_INFO, но если переменные указаны, то все, что следует за знаком "?" будет отброшено.
PATH_INFO ----------> "/cgi-bin/search?nuclear+isotop" SCRIPT+NAME --------> "/cgi-bin/search"
QUERY_STRING - переменная определяет содержание запроса к скрипту. Чрезвычайно важна при использовании метода доступа GET. Возвращаясь к примеру с адресами скрипта укажем, что в QUERY_STRING помещается все, что записано после символа "?".
QUERY_STRING -------> "nuclear+isotop"
При этом никакого преобразования строки запроса сервером не производится. Все манипулирования с содержанием QUERY_STRING возложены на скрипт.
Следующий набор переменных связан с идентификацией пользователя и его машины:
REMOTE_HOST - доменный адрес машины, с которой осуществляется запрос. REMOTE_ADDR - IP-адрес запрашивающей машины. AUTH_TYPE - тип идентификации пользователя. Используется в случае если скрипт защищен от несанкционированного использования. REMOTE_USER - используется для идентификации пользователя. REMOTE_IDENT - данная переменная порождается сервером, если он поддерживает идентификацию пользователя по протоколу RFC-931. Рекомендовано использование этой переменной для первоначального использования скрипта.
Следующие две переменные определяют тип и длину передаваемой информации от клиента к серверу.
CONTENT_TYPE - определяет MIME-тип данных, передаваемых скрипту. Используя эту переменную можно одним скриптом обрабатывать различные форматы данных. CONTENT_LENGTH - определяет размер данных в байтах, которые передаются скрипту. Данная переменная чрезвычайно важна при обмене данными по методу POST, т.к. нет другого способа определить размер данных, которые надо прочитать со стандартного ввода.
Возможна передача и других переменных окружения. В этом случае перед именем указывается префикс "HTTP_". Отдельный случай представляют переменные, порожденные в заголовке HTML-документа в тагах META. Они передаются в заголовке сообщения и некоторые серверы могут порождать переменные окружения из этих полей заголовка.
Подтип "digest"
предназначен для многоцелевого почтового сообщения, когда различным частям хотят приписать более детальную информацию, чем просто тип:
From: Moderator-Address MIME-Version: 1.0 Subject: Internet Digest, volume 42 Content-Type: multipart/digest; boundary="---- next message ----" ------ next message ---- From: someone-else Subject: my opinion ...body goes here ... ------ next message ---- From: someone-else-again Subject: my different opinion ... another body goes here... ------ next message ------
Приведенный пример показывает как можно воспользоваться подтипом "digest" для рассылки разным пользователям и по разному поводу почты, используя поля "From" и "Subject" в качестве частных заголовков.
Подтип "mixed"
может создавать сообщения, состоящие из нескольких фрагментов, которые разделены между собой границей, задаваемой в качестве параметра подтипа. Приведем простой пример:
From: Nathaniel Borenstein <nsb@bellcore.com> To: Ned Freed <ned@innosoft.com> Subject: Sample message MIME-Version: 1.0 Content-type: multipart/mixed; boundary="simple boundary" This is the preamble. It is to be ignored, though it is a handy place for mail composers to include an explanatory note to non-MIME compliant read ers. --simple boundary This is implicitly typed plain ASCII text. It does NOT end with a linebreak. --simple boundary Content-type: text/plain; charset=us-ascii This is explicitly typed plain ASCII text. It DOES end with a linebreak. --simple boundary-- This is the epilogue. It is also to be ignored.
В данном примере поле "Content-Type" определяет подтип "mixed" и границу между фрагментами, как строку "--simple boundary--". В начале каждого фрагмента может быть задана своя строка с полем "Content-Type". Как видно из примера, существует два фрагмента, которые не отображаются: преамбула и эпилог, в которые можно поместить комментарии.
Другим подтипом может быть подтип "alternative". Данный подтип позволяет организовать вариабельный просмотр почтового сообщения в зависимости от типа программы просмотра. Приведем пример:
From: Nathaniel Borenstein <nsb@bellcore.com> To: Ned Freed <ned@innosoft.com> Subject: Formatted text mail MIME-Version: 1.0 Content-Type: multipart/alternative; boundary=boundary42 --boundary42 Content-Type: text/plain; charset=us-ascii ...plain text version of message goes here.... --boundary42 Content-Type: text/richtext .... richtext version of same message goes here ... --boundary42 Content-Type: text/x-whatever .... fanciest formatted version of same message goes here ... --boundary42--
В этом примере для работы с планарным текстом при использовании алфавитно-цифровых программ просмотра предназначен первый фрагмент текста. Для просмотра размеченного текста используется второй фрагмент, для специальной программы просмотра может быть подготовлен специальный вариант (фрагмент 3).
Подтип "parallel"
предназначен для составления такого почтового сообщения, части которого должны отображаться одновременно, что предполагает запуск сразу нескольких программ просмотра. Синтаксис такого сообщения аналогичен рассмотренным выше.
Подтип "partial"
предназначен для передачи одного большого сообщения по частям для последующей автоматической сборки у получателя. Приведем пример передачи аудио-сообщения разбитого на части:
X-Weird-Header-1: Foo From: Bill@host.com To: joe@otherhost.com Subject: Audio mail Message-ID: id1@host.com MIME-Version: 1.0 Content-type: message/partial; id="ABC@host.com"; number=1; total=2 X-Weird-Header-1: Bar X-Weird-Header-2: Hello Message-ID: anotherid@foo.com Content-type: audio/basic Content-transfer-encoding: base64 ... first half of encoded audio data goes here... and the second half might look something like this: From: Bill@host.com To: joe@otherhost.com Subject: Audio mail MIME-Version: 1.0 Message-ID: id2@host.com Content-type: message/partial; id="ABC@host.com"; number=2; total=2 ... second half of encoded audio data goes here...
Атрибуты подтипа определяют идентификатор сообщения (id), номер порции (number) и общее число порций (total). Следует обратить внимание на то, что каждая часть имеет свое поле "Content-Type". Это означает, что все сообщение может состоять из частей разных типов.
Другим подтипом является "External-Body", который позволяет ссылаться на внешние, относительно сообщения, информационные источники. Приведем конкретный пример:
From: Whomever Subject: whatever MIME-Version: 1.0 Message-ID: id1@host.com Content-Type: multipart/alternative; boundary=42 --42 Content-Type: message/external-body; name="BodyFormats.ps"; site="thumper.bellcore.com"; access-type=ANON-FTP; directory="pub"; mode="image"; expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" Content-type: application/postscript --42 Content-Type: message/external-body; name="/u/nsb/writing/rfcs/RFC-XXXX.ps"; site="thumper.bellcore.com"; access-type=AFS expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" Content-type: application/postscript --42 Content-Type: message/external-body; access-type=mail-server server="listserv@bogus.bitnet"; expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" Content-type: application/postscript get rfc-xxxx doc --42--
В данном примере использованы "External-Body" и "multipart/alternative". Все сообщение разбито на несколько фрагментов. В каждом из фрагментов находится ссылка на внешний файл. Реально, тела почтового сообщения нет (границы программами просмотра не отображаются). Однако, если программа просмотра способна работать с внешними протоколами, то можно ссылки разрешить автоматически, запуская соответствующий сервис.
Стандартным подтипом типа "message" является "rfc822". Данный подтип определяет сообщения стандарта RFC-822.
Типы описания нетекстовой информации. Таких типов имеется четыре:
"image" для описания графических образов. Наиболее часто используются файлы форматов GIF и JPEG. "audio" для описания аудио-информации. Для воспроизведения сообщения данного типа требуется специальное оборудование. "video" для передачи фильмов. Наиболее популярным является формат MPEG. "application" для передачи данных любого другого формата. Обычно используется для передачи двоичных данных с последующим промежуточным преобразованием. Так, если на машине стоит видео-карта с 512Kb памяти, а графика подготовлена в 256 цветах, то сначала ее следует преобразовать и здесь может помочь тип "application". Основной подтип данного типа - "octet-stream", но существуют "ODA" и "Postscript". Назначение данных подтипов ясно из названия - обозначение данных для последующей обработки как данных в форматах, определяемых подтипом.
Поиск в нечетких множествах
При этом типе поиска весь массив документов описывается как набор нечетких множеств терминов. Каждый термин определяет некую монотонную функцию принадлежности документам документального массива. Когда запрашивается AND, то это интерпретируется как минимум из двух функций, соответствующих терминам запросов, OR - как максимум, NOT - как 1-<значение функции>. В соответствии с полученными значениями результат поиска также ранжируется, как и в случае с поиском по мерам близости.
Следует сразу сказать, что этот метод поиска используется только в исследовательских системах и распространен крайне ограничено.
Понятие гипертекста
В предыдущем разделе речь шла об истории и основных вехах развития World Wide Web. В последнее время часто приходится слышать, что WWW - это очень просто. Однако, за этой кажущейся простотой скрывается хорошо продуманная сложная система. При этом следует заметить, что система бурно развивается. Для того, чтобы более точно описать это развитие, наши англоязычные коллеги используют эпитет "dramatic". Познакомимся более подробно с WWW.
В 1989 году, когда Т.Бернерс-Ли предложил свою систему, в мире информационных технологий наблюдался повышенный интерес к новому и модному в то время направлению - гипертекстовым системам. Сама идея, но не термин, была введена В.Бушем (Vannevar Bush) в 1945 году в предложениях по созданию электромеханической информационной системы Memex. Несмотря на то, что Буш был советником по науке президента Рузвельта, идея не была реализована. В 1965 году Т.Нельсон (Ted Nelson) ввел в обращение сам термин "гипертекст", развил и даже реализовал некоторые идеи, связанные с работой с "нелинейными" текстами. В 1968 году изобретатель манипулятора "мышь" Д.Енжильбард (Doug Engelbart) продемонстрировал работу с системой, имеющей типичный гипертекстовый интерфейс, и, что интересно, проведена эта демонстрация была с использованием системы телекоммуникаций. Однако внятно описать свою систему он не смог. В 1975 году идея гипертекста нашла воплощение в информационной системе внутреннего распорядка атомного авианосца "Карл Винстон", которая получила название ZOG. В коммерческом варианте система известна как KMS. Работы в этом направлении продолжались и, время от времени, появлялись реализации типа HyperCard фирмы Apple или HyperNode фирмы Xerox. В 1987 была проведена первая специализированная конференция Hypertext'87, материалам которой был посвящен специальный выпуск журнала "Communication ACM".
Идея гипертекстовой информационной системы состоит в том, что пользователь имеет возможность просматривать документы (страницы текста) в том порядке, в котором ему это больше нравится, а не последовательно, как это принято при чтении книг. Поэтому Т.Нельсон и определил гипертекст как нелинейный текст. Достигается это путем создания специального механизма связи различных страниц текста при помощи гипертекстовых ссылок, т.е. у обычного текста есть ссылки типа "следующий-предыдущий", а у гипертекста можно построить еще сколь угодно много других ссылок. Любимыми примерами специалистов по гипертексту являются энциклопедии, Библия, системы типа "Help".
Простой, на первый взгляд, механизм построения ссылок оказывается довольно сложной задачей, т.к. можно построить статические ссылки, динамические ссылки, ассоциированные с документом в целом или только с отдельными его частями, т.е. контекстные ссылки. Дальнейшее развитие этого подхода приводит к расширению понятия гипертекста за счет других информационных ресурсов, включая графику, аудио- и видео-информацию, до понятия гипермедиа. Тем, кто интересуется более подробно различными схемами и способами разработки гипертекстовых систем, стоит обратиться к специальной литературе.
Пороговые модели
Как было видно из предыдущего изложения, на конечном этапе поиска выборка найденных документов ранжируется. Но, совершенно очевидно, что меры близости или поиск в нечетких множествах приводит к ранжированию всего массива документов в базе данных. Современные информационно-поисковые системы Internet имеют базы данных только индексов, занимающие террабайты. Ранжировать целиком такие массивы - это просто безумная затея. Поэтому применяются пороговые модели, которые задают пороговые значения для документов, выдаваемых пользователю.
POST
- этот метод разработан для передачи большого объема информации на сервер. Им пользуются для аннотирования существующих ресурсов, посылки почтовых сообщений, работы с формами интерфейсов к внешним базам данных и внешним исполняемым программам. В отличии от GET и HEAD, в POST передается тело ресурса, которое и является информацией из поля форм или других источников ввода. В первых версиях протокола были определены и другие методы доступа (DELETE, например), но они не нашли должного применения. Многие функции, которые возлагали на эти методы, можно успешно выполнять через POST.
Изменение числа методов доступа отражает практику использования HTTP. Однако, с исторической и методической точек зрения, первые версии протокола представляют несомненный интерес, особенно раздел, описывающий методы доступа. В версии 1993 года насчитывалось 13 различных методов доступа. Среди этих методов были такие, например, как:
CHECKOUT - защита от несанкционированного доступа; PUT - замена содержания информационного ресурса; DELETE - удаление ресурса; LINK - создание гипертекстовой ссылки; UNLINK - удаление гипертекстовой ссылки; SPACEJUMP - переход по координатам; SEARCH - поиск.
Из этого списка видно, что протокол был действительно максимально ориентирован на работу с гипертекстовыми распределенными системами, причем не только с точки зрения потребителя, но и с точки зрения разработчика подобных систем. Однако, во-первых, как показывал опыт, практически не использовались методы доступа, связанные с изменением информации. Это объясняется прежде всего соображениями безопасности. Ни один администратор не позволит неизвестно кому менять информацию на его сервере. Во-вторых, методы SPACEJUMP и SEARCH были с успехом заменены на функционально аналогичные CGI-скрипты. Из этого не следует, что их возрождение невозможно, например, в язык гипертекстовой разметки вернулись ссылки, общие для всего документа, но пока их реализация в протоколе отложена. В-третьих, не нашли практической реализации методы установления/удаления ссылок LINK и UNLINK. Но необходимость в них растет и связана она с реорганизацией сети. Многие информационные ресурсы меняют свои адреса, что вносит беспорядок в структуру сети, где и без этого начинающему пользователю трудно что-либо найти. Одним словом, вопрос о новых методах доступа все еще открыт, поэтому, видимо, спецификация HTTP еще не вышла на стадию RFC и остается в виде Internet Draft.
В обеих формах запроса важное место занимает форма запроса ресурса, которая кодируется в соответствии со спецификацией URI. Применительно к World Wide Web эта спецификация получила название URL. При обращении к серверу можно использовать как полную форму URL, так и упрощенную.
Полная форма содержит тип протокола доступа, адрес сервера ресурса, и адрес ресурса на сервере (рисунок 3.27).
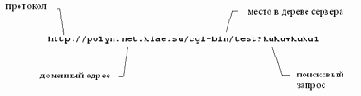
Рис. 3.27. Полный адрес ресурса
Однако такой адрес реально нужен для работы через промежуточный сервер, так как тот может пересылать запросы. При обращении к первичному серверу клиент может опускать протокол и адрес, устанавливая взаимодействие с сервером по адресу, указанному в URL (в исходном документе), и порту 80, передавая только путь от корня сервера.
Здесь пока оставим обсуждение элементов запроса и обратимся к структуре ответа сервера. Дело в том, что элементы заголовков запроса и ответа одинаковые, и поэтому их имеет смысл обсудить после определения структуры ответа сервера.
Правила преобразования адресов
. Это самая большая часть файла конфигурации программы sendmail. Преобразование адресов необходимо для принятия программой решений о пути рассылки почтовых сообщений, т.к. это решение принимается на основе полученного в результате преобразований почтового адреса.
Предварительные замечания
Информационно-поисковые системы появились на свет достаточно давно. Теории и практике построения таких систем посвящено довольно большое количество статей, основная масса которых приходится на конец 70-х - начало 80-х годов. Среди отечественных источников следует выделить научно-технический сборник "Научно-техническая информация. Серия 2. Информационные процессы и системы", который выходит до сих пор. На русском языке издана так же и "библия" по разработке этого рода систем - "Динамические библиотечно-информационные системы" Жерарда Солтона (Gerard Salton)[1] (список литературы приводится в конце учебного пособия), в которой рассмотрены основные принципы построения информационно-поисковых систем и моделирования процессов их функционирования. Таким образом нельзя сказать, что с появлением Internet и бурным вхождением его в практику информационного обеспечения, появилось нечто принципиально новое, чего не было раньше. Если быть точным, то информационно-поисковые системы в Internet - это признание того, что ни иерархическая модель Gopher, ни гипертекстовая модель World Wide Web не решают проблему поиска информации в больших объемах разнородных документов. И на сегодняшний день нет другого способа быстрого поиска данных, кроме поиска по ключевым словам.
При использовании иерархической модели Gopher приходится довольно долго бродить по дереву каталогов, пока не встретишь нужную информацию. Эти каталоги должны кем-то поддерживаться и при этом их тематическое разбиение должно совпадать с информационными потребностями пользователя. Учитывая анархичность Internet и огромное количество всевозможных интересов у пользователей Сети, понятно, что кому-то может и не повезти, и в сети не будет каталога отражающего конкретную предметную область. именно по этой причине для множества серверов Gopher, которое называется GopherSpace была разработана информационно-поисковая программа Veronica (Very Easy Rodent-Oriented Net-wide Index of Computerized Archives).
Аналогичное развитие событий мы видим и в World Wide Web. Собственно еще в 1988 году на в специальном выпуске "Communication of the acm"[2] среди прочих проблем разработки гипертекстовых систем и их использования Франк Халаз назвал проблему организации поиска информации в больших гипертекстовых сетях в качестве первоочередной задачи для следующего поколения систем этого типа. До сих пор многие идеи, высказанные в этом разделе, не нашли еще своей реализации. Естественно, что система, предложенная Бернерсом-Ли[3] и получившая такое широкое распространение в Internet, должна была столкнуться с теми же проблемами, что и ее локальные предшественники. Реальное подтверждение этому было продемонстрировано на второй конференции по World Wide Web осенью 1994 года, на которой были представлены доклады о разработке информационно-поисковых систем для Web, а система World Wide Web Worm, разработанная Оливером МакБрайном из Университета Колорадо, получила приз как лучшее навигационное средство. Следует также отметить, что все-таки долгая жизнь суждена не хорошим программам талантливых одиночек, а средствам, которые являются результатом долгосрочного планирования последовательного движения к поставленной цели научных и производственных коллективов. Рано или поздно этап исследований заканчивается и наступает этап эксплуатации систем, а это уже совсем другой род деятельности. Именно такая судьба ожидала два других проекта, представленных на той же конференции: Lycos, поддерживаемый компанией Microsoft, и WebCrawler, ставший собственностью America On-line.
Разработка новых информационных систем для Web не завершена. Причем как на стадии написания коммерческих систем, так и на стадии исследований. За прошедшие два года снят только верхний слой возможных решений. Однако, многие проблемы, которые ставит перед разработчиками ИПС Internet не решены до сих пор. Именно этим обстоятельством и вызвано появление проектов типа AltaVista компании Digital[4], главной целью которого является разработка программных средств информационного поиска для Web и подбор архитектуры для информационного сервера Web.
Primary
- определяет зону, для которой данный сервер является primary server, и имя файла базы данных этой зоны. Файл размещается в директории, которая указана в команде directory.
Primary server
- это основной сервер зоны . В его базе данных описывается соответствие доменных имен и IP-адресов для машин, принадлежащих данной зоне. База данных сервера хранится на том же компьютере, где и функционирует сервер доменных имен. При запуске сервера последний обращается к файлам своей базы данных, после чего он становится способным отвечать на запросы разрешения доменных имен IP-адресами и обратно.
Применение языков на практике
Рассмотрим теперь небольшой сравнительный пример использования описанных выше поисковых машин. В качестве запроса использовалась фраза: "Best on the Web"
Подразумевалось, что следует найти документ, связанный с конкурсами "Лучший на Сети". Понятно, что уже в самом запросе есть определенная некорректность, но тем интереснее посмотреть, как с ней справились различные системы. Эта фраза задавалась в качестве набора слов и при этом получались следующие результаты.
Фрагмент статистики сервера при обращении
. Фрагмент статистики сервера при обращении к базе данных "Полынь"
144.206.192.4 - - [15/Sep/1995:23:17:29 -0400] "GET /dss/index.htm HTTP/1.0" 200 1020 144.206.192.4 - - [15/Sep/1995:23:17:30 -0400] "GET /dss/radsign1.gif HTTP/1.0" 200 270 144.206.192.4 - - [15/Sep/1995:23:17:56 -0400] "GET /dss/index.htm?kuku HTTP/1.0" 200 1020
Разберем первую строчку журнала посещений, представленного в примере:
144.206.192.4 - адрес хоста, с которого осуществлялся доступ к базе данных;
"- -" - сообщает, что северу не был переданы ни имя пользователя, ни запрос на идентификацию;
[15/Sep/1995:23:17:29 -0400] - дата и время доступа;
GET /dss/index.htm HTTP 1.0 - запрос клиента;
200 - код успешного завершения обработки запроса;
1020 - число переданных клиенту байтов.
Первые две строчки этого примера составляют одно посещение, т.к. страница "index.htm" содержит картинку "radsign1.gif". Таким образом журнал посещений содержит информацию о доступе к файлам базы данных, из которой еще надо составить статистику доступа к страницам.
Кроме файла посещений, который обычно называется access_log, многие серверы ведут еще и другие системные журналы, например, error_log (журнал ошибок), referer_log (журнал страниц, в которых установлены ссылки на данную страницу), agent_log (журнал программного обеспечения клиентов).
В нашем случае сосредоточим внимание на журнале посещений, т.к. именно он является источником статистики, которую будем анализировать в дальнейшем.
Существует достаточно большой набор программного обеспечения, которое можно использовать для получения простейших статистических оценок. Здесь мы рассмотрим программы: Analog, AccessWatch, Web-Scope, Statbot, mw3s, Raytraced Access Stats.
Analog - программа, разработанная Стефеном Тернером (Stephen Turner) из лаборатории статистики Кембриджского Университета, считается одной из лучших среди свободно распространяемых средств анализа статистики Web. Она выдает статистику в виде ASCII файлов, в которых содержится и графическое представление в виде, принятом для просмотра на алфавитно-цифровых дисплеях. Считается, что если понадобится построить качественные картинки, то лучше использовать специальное программное обеспечение для их подготовки. Analog анализирует файлы посещений в "старом" формате сервера NCSA и "общем" формате, который был описан выше. Программа подготавливает сводный отчет, в который входит общее количество посещений сервера за анализируемый период, общие число ошибок за исследуемый период, число перенаправлений, средние число запросов в день, число обслуженных хостов, количество страниц, с которых осуществлялся доступ, число некорректных записей в файле посещений, общее число байтов переданных клиентам и среднее число байтов переданных за сутки. Analog генерирует месячный отчет по доступу к базе данных, недельный отчет и несколько видов суточных отчетов: сводный отчет по дням недели, и отчет по датам. Подсчитывается частота обращений с различных доменов, с различных хостов, и выводится в упорядоченном по частоте виде. Для анализа популярности страниц приводится статистика посещения директорий и отдельных страниц базы данных. В конце отчета приводится время, за которое отчет был подготовлен, и версия программы. Программа может быть получена по адресу: ftp://ftp.statslab.cam.ac.uk/pub/users/sret1/analog/.
AccessWatch - это скрипт, написанный на Perl 5.0 Дейвом Маером (Dave Maher) из университета Бакнел, который позволяет собирать статистику не только по серверу в целом, но и по отдельным домашним страницам пользователей. Для работы с этой программой желательно иметь программу просмотра страниц Web, которая позволяет отображать таблицы HTML. Последнее необходимо для представления данных в виде столбцов гистограмм. Такой метод представления статистики в программах анализа журналов посещений довольно популярен и не только в свободно-распространяемых программах, но в коммерческих продуктах. AccessWatch генерирует отчет о суточной статистике посещений, почасовую статистику посещений, упорядоченное по частоте посещений распределение страниц, частоту посещения с разных доменов, упорядоченный список 10 наиболее активных хостов. Адрес AccessWatch: http://www.eg.bucknell.edu/~dmaher/accesswatch/.
Mw3s - это одна из версий Multi Server WebChats (v1.4.1), которая разработана Тобиасом Оетакером(Tobias Oetiker) из университета De Montfort, Англия. Главное назначение этого пакета - сбор статистики с нескольких http серверов. Пакет состоит из двух программ. Первая - logscan устанавливается как CGI-скрипт на каждом сервере, который будет находится под присмотром mw3s. Вторая - loggather, который устанавливается в crontab машины, осуществляющей мониторинг. Loggather запускается системой один раз в сутки, порождая при этом запросы к logscan. Mw3s, также как и AccessWatch, использует механизм таблиц HTML для отрисовки столбцов гистограмм. Скрипты можно получить по адресу: ftp://ftp.dmu.ac.uk/pub/netcomm/src/web/.
Statbot - программа генерации статистических отчетов о посещении Web страниц, которая поддерживается Дейвом Табсом (Dave Tubbs, dttubbs@xmission.com). Statbot генерирует графические отчеты в формате GIF, ссылки на которые могут быть включены в другие HTML-страницы. Генерируется 8 различных графиков-гистограмм: трафик за последние семь дней, трафик за последние 24 часа, сравнительный график трафика за последние четыре недели (каждая неделя отображается своим цветом), графики максимального и среднего трафика для каждого дня недели, график 10 наиболее активных машин, график соотношения общего посещения каждой страницы к числу повторных посещений этой же страницы (каждая страница отображается на графике отдельной точкой), круговая диаграмма распределения посещений по доменам и график общего числа байтов переданных с данного сервера в день. Программа может быть получена по адресу: ftp://ftp.xmission.com/pub/users/d/dtubbs/.
Web-Scope - пакет анализа статистики посещений, разработанная для TCL System Corporation. Пакет состоит из двух частей: программы построения дополнительных журналов и программы отображения данных. Среди обычного набора графиков и гистограмм следует отметить те, которые направлены на анализ информации о пути достижения страниц базы данных (где находятся ссылки на страницы, внесены ли эти ссылки в файлы закладок, какие роботы посещают страницы и какую информацию они ищут). Информацию о пакете можно найти по адресу: http://www.tic-systems.com/statinfo.html.
Raytraced Access Stats - программа подготовки данных для отображения программой POV raytracer. Главным достоинством этой программы является наличие прекрасной трехмерной графики, которая используется для построения гистограмм. Правда, воспользоваться этой красотой может только тот, кто соберет POV raytracer для своей платформы. Информацию о программе можно получить по адресу: http://web.sau.edu/ ~mkruse/scripts/access3.html
Цель анализа любой статистики обращений к информационной системе - это повышение эффективности работы этой системы, однако само понятие эффективности может быть истолковано по разному. Для коммерческих систем - эффективность будет исчисляться в терминах приносимой системой прибыли, в то время, как эффективность информационной системы бюджетной организации может исчисляться на основании числа реальных пользователей системы, количества запросов и, косвенно, на основе доли бюджетных средств, которые на систему тратятся. В данном разделе речь пойдет об анализе статистики посещений с целью повышения коммерческой эффективности системы. В первую очередь полученные результаты применимы для анализа статистики посещений рекламных материалов и расчета времени и, соответственно, затрат на размещение рекламы на страницах World Wide Web.
Приведем результаты обращений к данным сервера за семь месяцев его эксплуатации, собранные при помощи стандартных программ обработки статистики посещений:
в этой таблице является необязательным.
Содержание файла /etc/hosts
127.0.0.1 localhost 144.206.130.137 polyn Polyn polyn.net.kiae.su polynm.kiae.su 144.206.160.32 polyn Polyn polyn.net.kiae.su polyn.kiae.su 144.206.160.40 apollo Apollo www.polyn.kiae.su
Последний столбец в этой таблице является необязательным. Пользователь для обращения к машине может использовать как IP-адрес машины, так и ее имя или синоним (alias). Как видно из примера, синонимов может быть много, и, кроме того для разных IP-адресов может быть указано одно и то же имя.
Обращения, приведенные ниже, приводят к одному и тому же результату - инициированию сеанса telnet с машиной Apollo:
telnet 144.206.160.40 или telnet Apollo или telnet www
В локальных сетях файлы hosts используются достаточно успешно до сих пор. Практически все операционные системы от различных клонов Unix до Windows NT поддерживают эту систему соответствия IP-адресов доменным именам.
Однако такой способ присвоения символьных имен был хорош до тех пор, пока Internet был маленьким. По мере роста сети стало затруднительным держать большие списки имен на каждом компьютере. Для того, что бы решить эту проблему, были придуманы DNS (Domain Name System).
это комментарии. Среди них следует
. Содержание файла resolv.conf.
# Resolver config for paul. # #nonameserver domain polyn.kiae.su nameserver 144.206.130.137 nameserver 144.206.136.1
Строки, начинающиеся с символа "#" - это комментарии. Среди них следует выделить строку "nonameserver". В нашем примере она не влияет на работу системы разрешения доменных имен, но если в сети нет сервера доменных имен, то следует с этой строки снять символ комментария, а прочие команды напротив превратить в комментарии. При отсутствии сервера доменных имен система будет использовать файл hosts.
По команде domain система определяет к какому домену она относится. Обычно, именем, которое указано после команды расширяются неполные имена хостов. Например, если обратиться к какой-либо машине только по ее имени:
/usr/paul> telnet radleg
Указанный выше пример - это только частный случай процедуры расширения неполного имени, которая используется функциями resolver. В общем виде она выглядит следующим образом:
Если в прикладной программе указано имя хоста с точкой на конце, то расширение имени не производится:
/usr/paul>ping polyn.
В данном случае имя "polyn." завершено точкой. Если имя указано без точки, расширение производится по следующим правилам: либо происходит добавление имени домена, либо происходит обращение к файлу синонимов. Вообще говоря, в различных системах это расширение может быть организовано различными способами. Например, HP-UX имя фала синонимов указывается в переменной окружения HOSTALIASES. Пример расширения доменным именем был приведен выше. Если в качестве имени указывается составное имя, то производится серия подстановок, при помощи которых пытаются получить IP-адрес хоста:
/usr/paul> ping paul.polyn.kiae
Если в качестве домена в resolv.conf указан домен polyn.kiae.su, то будет проверена следующая последовательность имен: paul.polyn.kiae.polyn.kiae.su; paul.polyn.polyn.kiae.su; paul.polyn.kiae.su. Последнее имя будет разрешено сервером доменных имен.
При указании имени домена следует также учитывать и то, как будет в этом случае работать вес комплекс программного обеспечения, установленный на данном компьютере. Дело в том, что некоторые программы, sendmail, например, способны сами решат проблему определения IP-адресов по именам. В ряде случаев это может привести к противоречиям и ошибкам при функционировании такого сорта программ (о настройках sendmail см. раздел "Электронная почта")
Команда nameserver определяет адрес сервера доменных имен для домена, в котором данная машина состоит. Возможно указание нескольких серверов. Обычно - это не более трех серверов доменных имен. В таких системах как Windows NT, например, администратор просто не в состоянии указать более трех адресов серверов доменных имен.
Порядок в указании серверов в файле resolv.conf определяет порядок опроса серверов. Таким образом первым в нашем случае будет опрашиваться сервер с адресом 144.206.130.137, а затем сервер с адресом 144.206.136.1. Наиболее целесообразно первым указывать основной сервер доменных имен данного домена, а вторым дублирующий сервер доменных имен данного домена .
В качестве сервера доменных имен можно также указать и сервер вышестоящего домена, что позволит подстраховаться на случай отказа основного и вспомогательного серверов. При этом не будут решены проблемы адресации машин данного домена, но зато не пропадет возможность обращаться по имени к машинам, расположенным за пределами домена.
В настройках resolver надо также учитывать возможность запуска программы named, которая будет работать как кэш-сервер, что на машинах с "интеллектуальным" resolver'ом, что позволяет обеспечить более эффективную процедуру разрешения запросов к системе DNS.
От этой директории затем идет
Содержание файла named.boot
;An Example of the named.boot ; directory namedb primary 0.0.127.in-addr.arpa localhost primary vega.ru vega primary 43.226.194.in-addr.arpa vega.rev secondary polyn.kiae.su 144.206.130.137 144.206.192.34 polyn secondary 160.206.144.in-addr.arpa 144.206.130.137 144.206.192.34 polyn.rev cache . named.root
Обычно, файл named.boot размещается в директории /etc. От этой директории затем идет отсчет места компонентов базы данных named. В нашем случае эту базу данных можно представить в виде графа (рисунок 3.10), у которого в качестве корня выступает директория /etc. В /etc существует поддиректория namedb, в которой располагаются все остальные файлы.
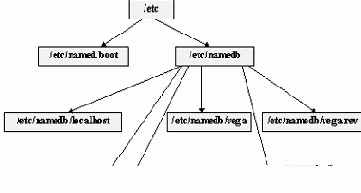
Рис.3.10. Структура размещения файлов базы данных named из примера 3
Сопоставив рисунок 3.10 и описание из примера 3, легко догадаться, что последняя колонка в каждой из команд описания настроек named заканчивается именем соответствующего файла или директории. Рассмотрим формат каждой команды более подробно.
Команда directory определяет директорию namedb как директорию размещения файлов базы данных named. Вообще говоря, вовсе не так уж обязательно размещать все файлы в одной директории. Можно создать несколько директорий, например, по количеству зон. Christophe Wolfhugel, например, для каждой зоны использует отдельную поддиректорию в корневой директории named. Если придерживаться этой логики размещения файлов, то получим следующее.
boot при размещении файлов описания
Содержание файла named. boot при размещении файлов описания зон для primary и secondary серверов по разным директориям
;An Example of the named.boot ; directory namedb primary 0.0.127.in-addr.arpa localhost primary vega.ru v/vega primary 43.226.194.in-addr.arpa v/vega.rev secondary polyn.kiae.su 144.206.130.137 144.206.192.34 p/polyn secondary 160.206.144.in-addr.arpa 144.206.130.137 144.206.192.34 p/polyn.rev cache . named.root
В примере 4 в директории namedb определены две поддиректории v и p. В директории v размещаются файлы зон vega.ru и 43.226.194.in-addr.arpa, для которых данный сервер является primary. В свою очередь в директории p размещаются файлы описания зон polyn.kiae.su и 160.206.144.in-addr.arpa, для которых данный сервер является secondary сервером. Если представить структуру файлов в виде графа, то получится граф типа графа на рисунке 3.11.
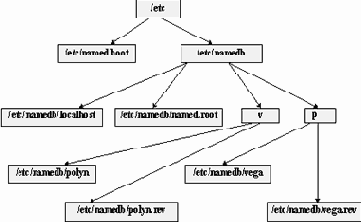
Рис. 3.11. Дерево файлов описания базы данных named из примера 4
Вообще говоря, корнем описания файлов базы данных named может быть директория отлична от /etc. Если программу named запустить с флагом "-f", то в качестве параметра можно указать полный путь к файлу named.boot или к другому файлу, который используется вместо named.boot:
/usr/paul>named -f /usr/paul/named.par
В этом случае в качестве корневой директории для файлов описания базы данных named будет использоваться директория /usr/paul, а в качестве файла named.boot файл named.par из этой директории.
Кроме того, в команде directory, как это определено в наших примерах, используется, так называемый, неполный путь к директории, где расположены файлы базы данных named. Однако, можно указывать и полный путь, что дает возможность расположить эти файлы где угодно в файловой системе сервера. Например, если файлы расположены в директории /usr/local/etc/namedb, то в файле named.boot следует указать следующую команду directory:
directory /usr/local/etc/namedb
Команда primary используется для указания зоны, для которой данный сервер выступает как primary сервер, и указания имени файла, который эту зону описывает. Формат команды primary можно описать следующим образом:
Servers from the root domain
. Файл cache (Февраль 1996 года)
; Servers from the root domain ; ftp://nic.ddn.mil/netinfo/root-servers.txt . 99999999 IN NS A.ROOT-SERVERS.NET . 99999999 IN NS B.ROOT-SERVERS.NET . 99999999 IN NS C.ROOT-SERVERS.NET . 99999999 IN NS D.ROOT-SERVERS.NET . 99999999 IN NS E.ROOT-SERVERS.NET . 99999999 IN NS F.ROOT-SERVERS.NET . 99999999 IN NS G.ROOT-SERVERS.NET . 99999999 IN NS H.ROOT-SERVERS.NET . 99999999 IN NS I.ROOT-SERVERS.NET ; Root servers by address A.ROOT-SERVERS.NET 99999999 IN A 198.41.0.4 B.ROOT-SERVERS.NET 99999999 IN A 128.9.0.107 C.ROOT-SERVERS.NET 99999999 IN A 192.33.4.12 D.ROOT-SERVERS.NET 99999999 IN A 128.8.10.90 E.ROOT-SERVERS.NET 99999999 IN A 192.203.230.10 F.ROOT-SERVERS.NET 99999999 IN A 192.5.5.241 G.ROOT-SERVERS.NET 99999999 IN A 192.112.36.4 H.ROOT-SERVERS.NET 99999999 IN A 128.63.2.53 I.ROOT-SERVERS.NET 99999999 IN A 192.36.148.17
Формат записей этого файла мы обсудим позже при рассмотрении форматов записей файлов базы данных описания зоны.
Все что было сказано о содержании файла из команды cache относится к случаю, когда в качестве имени зоны указана ".". Это означает, что описывается корневая зона, что в свою очередь означает описание корневых серверов доменных имен, к которым named обращается при работе в режиме нерекурсивной процедуры разрешения запросов на IP-адрес по имени или запросов на имя по IP-адресу.
Если в файл chache необходимо внести другую информацию, то это делается аналогично описанию корневых серверов. Реализация файла cache, отличного от указанного в примере 5 будет рассмотрена для случая делегирования зоны в домене.
Команда forwarders определяет IP-адреса серверов, на которые следует отправлять неразрешенные данным сервером запросы. Команда имеет следующий вид:
forwarders <список IP-адресов серверов>
Случай организации рекурсивной процедуры разрешения имени с использованием этой команды был рассмотрен ранее. Однако этим случаем не ограничивается круг использования команды forwarders. При регистрации домена некоторое время внешний (относительно этого домена) мир не подозревает о существовании домена. Должно пройти некоторое время, прежде чем будет закончена процедура регистрации домена и обновления баз данных вышестоящего в иерархии DNS домена на всех серверах как primary, так и secondary. Однако внутри домена все работает нормально, т.к. сервер запускается до официальной регистрации и способен обслуживать машины домена. Однако, он может и не знать информации о всех доменах Internet. По этой причине всегда полезно указать команду forwarders на сервер домена вышестоящего относительно данного домена. Так, например, для зоны polyn.kiae.su сервером домена kiae.su, в который входит данная зона, является сервер с IP-адресом 144.206.136.1. Для того, чтобы пересылать на него запросы на разрешение имен IP-адресами в named.boot следует включить команду:
forwarders 144.206.136.1
Обычно указывают не один, а несколько IP-адресов серверов, которые в состоянии ответить на запросы клиентов, на которые данный сервер ответить не может. Например для сервера зоны vega.ru, который запущен, но еще не зарегистрирован, можно указать два сервера:
forwarders 144.206.136.1 144.206.130.137
Команда slave указывается тогда, когда сервер общается с внешним миром через серверы-посредники, указанные в команде forwarders. Параметров у данной команды нет. Файл named.boot для того сервера, если он еще и primary сервер для зон vega.ru и 43.226.194.in-addr.arpa будет выглядеть так, как показано в примере 6.
Подчиненный сервер, работающий по рекурсивной
. Подчиненный сервер, работающий по рекурсивной процедуре разрешения запросов от resolver
;An Example of the named.boot ; directory namedb primary 0.0.127.in-addr.arpa localhost primary vega.ru vega primary 43.226.194.in-addr.arpa vega.rev cache . named.root forwarders 144.206.130.137 144.206.136.1 slave
Фактически, команда slave позволяет организовать, в некотором смысле, "интеллектуальный" resolver.
Перейдем теперь к описанию содержания файлов базы данных named. Все эти файлы состоят из записей, которые имеют одинаковый формат и называются записями описания ресурсов.
Формат записи определяется документом RFC-1033, и имеет следующий вид:
<name> <ttl> <class> <type> <data>
Все поля отделяются друг от друга пробелом или табуляцией. Каждое из них имеет следующее значение:
Поле name - это имя объекта. Объектом может быть хост, домен и поддомен. Существуют специальные правила именования объектов, которые базируются на понятии текущего имени домена. Программа named анализирует файл базы данных начиная с первой записи последовательно до последней записи файла. Первоначально текущим именем домена является имя, указанное в командах primary, secondary или cache файла named.boot, в зависимости от того о каком файле базы данных named идет речь, если первая запись этого файла содержит имя @. В противном случае для определения текущего имени должна быть указана команда $ORIGIN. Если имя в записи описания ресурса опущено, то ресурс относится к текущему имени домена. Если имя указано без точки на конце, то оно расширяется текущим именем домена. Для изменения текущего имени домена следует ввести либо команду $ORI-GIN, либо указать имя записи ресурса с точкой на конце. Если в качестве имени указана одна точка (".") или две точки ("..") то такая запись описывает домен root, т.е. корневой домен. Если в имени записи встречается символ "*", то это он означает что вместо него можно подразумевать любую разрешенную последовательность символов. В англоязычных источниках это называют "wildcard character". Для пользователей любой операционной системы употребление этого символа хорошо знакомо по командам dir (MS-DOS) или ls (Unix). Например, при необходимости получить список файлов, оканчивающихся расширением "bak", выдается команда:
Примеры настроек программы named и описания зон
В данном разделе мы рассмотрим наиболее типичные, на мой взгляд, примеры построения сервиса доменных имен:
описание простой "прямой" и "обратной" зон в домене ru; описание "прямой" и "обратной" зон для поддомена, определенного на двух подсетях; делегирование поддоменов внутри домена.
Этот перечень можно было бы и расширить, но такое расширение будет просто комбинацией приведенных выше случаев. Более сложные случаи встречаются в практике администраторов больших сетей, и для них можно только порекомендовать обращаться за помощью к другим администраторам или разработчикам программ-серверов.
С первой ситуацией сталкивается любая организация, которая намеривается получить свой собственный домен в домене ru. О том, как его получить рассказывалось в разделе 3.1.3. В настоящее время практически нет сетей класса B, поэтому организации получают сети класса C на 254 машины и на основе этих сетей организовывают свой домен. В самом начале такой домен, как правило состоит из одной единственной зоны. В качестве главной машины в этом домене выступает один единственный компьютер с операционной системой Unix или Windows NT. Все остальные варианты рассматривать не будем в силу их неготовности для полноценной работы с сервисом доменных имен Internet. Этот компьютер одновременно является и шлюзом между локальной сетью и сетью Internet-провайдера.
Второй случай касается ситуации, когда сеть учреждения приходится разбивать на подсети. При этом на нескольких подсетях может быть определена одна и та же зона общего домена организации. Такая ситуация часто возникает при постоянных перемещениях подразделений из одного помещения в другое или даже из одного здания в другое. При этом часто подразделения либо съезжаются, либо разъезжаются. Случай типичный для растущей или стареющей организации.
Третий случай обусловлен развитием и усложнением сети или структуры организации, которую данная сеть обслуживает. Когда становится трудно управлять из одного места всеми машинами в домене, права управления частями домена делегируют туда, где изменения наиболее часты. В этом случае администратор домена снимает с себя часть обязательств по управлению доменом и передает их администраторам поддоменов. Для больших организаций - это типичный способ обеспечения сервиса доменных имен. Можно, конечно, спорить о достоинствах или недостатках такого делегирования прав, но в современных условиях это единственная возможность управлять большими разнородными сетями.
Принципы организации
Электронная почта во многом похожа на обычную почтовую службу. Корреспонденция, подготавливается пользователем на своем рабочем месте либо программой подготовки почты, либо просто обычным текстовым редактором. Обычно, программа подготовки почты вызывает текстовый редактор, который пользователь предпочитает всем остальным программам этого типа. Затем пользователь должен вызвать программу отправки почты (программа подготовки почты вызывает программу отправки автоматически). Стандартной программой отправки является программа sendmail. Sendmail работает как почтовый курьер, который доставляет обычную почту в отделение связи для дальнейшей рассылки. В Unix-системах sendmail сама является отделением связи. Она сортирует почту и рассылает ее адресатам. Для пользователей персональных компьютеров, имеющих почтовые ящики на своих машинах и работающих с почтовыми серверами через коммутируемые телефонные линии, могут потребоваться дополнительные действия. Так, например, пользователи почтовой службы Relcom должны запускать программу UUPC, которая осуществляет доставку почты на почтовый сервер.
Для работы электронной почты в Internet разработан специальный протокол Simple Mail Transfer Protocol (SMTP), который является протоколом прикладного уровня и использует транспортный протокол TCP. Однако, совместно с этим протоколом используется и Unix-Unix-CoPy (UUCP) протокол. UUCP хорошо подходит для использования телефонных линий связи. Большинство пользователей электронной почты Relcom реально пользуются для доставки почты на узел именно этим протоколом. Разница между SMTP и UUCP заключается в том, что при использовании первого протокола sendmail пытается найти машину-получателя почты и установить с ней взаимодействие в режиме on-line для того, чтобы передать почту в ее почтовый ящик. В случае использования SMTP почта достигает почтового ящика получателя за считанные минуты и время получения сообщения зависит только от того, как часто получатель просматривает свой почтовый ящик. При использовании UUCP почта передается по принципу "stop-go", т.е. почтовое сообщение передается по цепочке почтовых серверов от одной машины к другой пока не достигнет машины-получателя или не будет отвергнуто по причине отсутствия абонента-получателя. С одной стороны, UUCP позволяет доставлять почту по плохим телефонным каналам, т.к. не требуется поддерживать линию в течении времени доставки от отправителя к получателю, а с другой стороны бывает обидно получить возврат сообщения через сутки после его отправки из-за того, что допущена ошибка в имени пользователя. В целом же общие рекомендации таковы: если имеется возможность надежно работать в режиме on-line и это является нормой, то следует настраивать почту для работы по протоколу SMTP, если линии связи плохие или on-line используется чрезвычайно редко, то лучше использовать UUCP.
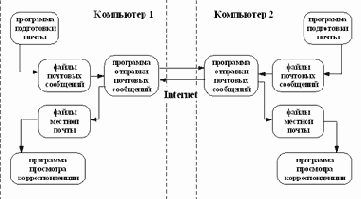
Рис. 3.14. Структура взаимодействия участников почтового обмена
Основой любой почтовой службы является система адресов. Без точного адреса невозможно доставить почту адресату. В Internet принята система адресов, которая базируется на доменном адресе машины, подключенной к сети. Например, для пользователя paul машины с адресом polyn.net.kiae.su почтовый адрес будет выглядеть как:
paul@polyn.net.kiae.su.
Таким образом, адрес состоит из двух частей: идентификатора пользователя, который записывается перед знаком "коммерческого @", и доменного адреса машины, который записывается после знака "@". Адрес UUCP был бы записан как строка вида:
net.kiae.su!polyn!paul
Программа рассылки почты Sendmail сама преобразует адреса формата Internet в адреса формата UUCP, если доставка сообщения осуществляется по этому протоколу.
Принципы организации DNS
Любая DNS является прикладным процессом, который работает над стеком TCP/IP. Таким образом, базовым элементом адресации является IP-адрес, а доменная адресация выполняет роль сервиса. Правда о том, что DNS - это прикладная задача в полном смысле этого слова приходится говорить с определенными оговорками. DNS - это информационный сервис Internet, и, следовательно, протоколы его реализующие относятся к протоколам прикладного уровня согласно стандартной модели OSI. Однако с точки зрения операционной системы поддержка DNS может входить в нее как компонента ядра, которая прикладным пользовательским процессом не является. Пользовательские программы общаются с ней при помощи системных вызовов. Такое положение вещей справедливо практически для всех Unix-систем. Другое дело системы на базе MS-DOS и Windows 3.x. В этих системах DNS (точнее ее клиентская часть) реализована как прикладная программа.
Система доменных адресов строится по иерархическому принципу. Однако иерархия эта не строгая. Фактически, нет единого корня всех доменов Internet. Если быть более точным, то такой корень в модели DNS есть. Он так и называется "ROOT". Однако, единого администрирования этого корня нет. Администрирование начинается с доменов верхнего, или первого, уровня. В 80-е годы были определены первые домены этого уровня: gov, mil, edu, com, net. Позднее, когда сеть перешагнула национальные границы США появились национальные домены типа:
Программа named
К сожалению достаточно подробной единой документации по named, в которой было бы приведено достаточно большое множество примеров описания файлов настроек named для различных конфигураций доменов, в природе (в архивах сети Internet, да и в книгах, посвященных проблеме администрирования сетей TCP/IP) не существует. Данное описание также не претендует на полный обзор возможностей named, но позволяет некоторым образом упорядочить представление об этих возможностях. Кроме того, в данном разделе приводятся примеры из практики настройки этого сервера доменных имен, которые могут быть полезны в практической работе и отражают наиболее типичные случаи организации доменов.
Программа named является одним из наиболее популярных серверов доменных имен из тех, что используются в Internet. Для своей работы она использует 53 порты TCP и UDP.
При разработке named была реализована концепция функционирования трех типов серверов доменных имен: primary, secondary, cache. Если быть более точным, то named может одновременно выполнять функции всех трех типов серверов.
Программа nslookup
Описать зону - это только полдела. После установки следует убедиться, что все работает нормально. Другой случай, когда необходим контроль за работой сервера DNS - жалобы пользователей. При этом смотреть свои собственные файлы дело бесполезное, т.к. в них скорее всего ошибок нет, т.к. сервер эксплуатируется уже некоторое время. Едиственный способ убедиться в том, что все работает так, как надо - проиметировать работу системы, взаимодействующей с сервером. Именно эту задачу и решает программа nslookup.
Программа может использоваться в интерактивном режиме и в режиме генерации отчета о разовом запросе. Наиболее часто используют интерактивный способ тестирования. Для интерактивного тестирования достаточно просто вызвать программу по имени при этом в качестве сервера будет взят сервер, указанный в файле конфигурации resolver:
/usr/paul>nslookup > 144.206.192.1 Server: arch.kiae.su Address: 144.206.136.10 Name: quest.polyn.kiae.su Address: 144.206.192.1 >exit
В данном конкретном примере цель запроса состояла в получении имени машины по ее IP-адресу. Возможна и обратная операция, т.е. получение IP-адреса по имени:
/usr/paul>nslookup > polyn.net.kiae.su Server: arch.kiae.su Address: 144.206.136.10 .... Address: 144.206.192.1 >exit
Однако, тестирование имен с локального сервера только проверяет как resolver работает с этим локальным сервером. Для того, чтобы проверить, как имена вашего домена разрешаются с другого сервера доменных имен, следует изменить текущий сервер доменных имен, используемый nslookup в качестве первого при разрешении доменного имени:
> server vega.ru Default Server: vega.ru Address: 194.226.43.1 >
В данном случае в качестве текущего сервера выбран сервер vega.ru. После изменения адреса текущего сервера можно снова проверить адреса имен вашего домена на доступность для сервиса доменных имен.
При помощи nslookup можно посмотреть содержание записей базы данных описания зоны. Делается это несколькими способами. Первый из них - это установка типа записей:
> set querytypa=SOA > polyn.kiae.su Server: vega.ru Address: 194.226.43.1 polyn.kiae.su origin = polyn.net.kiae.su mail addr = paul.kiae.su serial = 36 refresh = 3600 (1 hour) retry = 300 (5 mins) expire = 9999999 ( 115 days 17 hours 46 mins 39 secs) minimum ttl = 3600 (1 hour) polyn.kiae.su nameserver = polyn.net.kiae.su polyn.kiae.su nameserver = ns.kiae.su >
В данном случае установлен тип записи для просмотра - SOA, после этого задано имя polyn.kiae.su. В этовет на этот запрос сервер нашел другой сервер, в зону ответственности которого входит данное имя и распечатал запись SOA для этой зоны. При этом все поля распечатываются в понятном для чтения виде.
Другой способ заключается в том, чтобы исполбзовать команду ls:
>ls -t soa polyn.kiae.su .... список записей зоны ..... >
Если необходимо проконтролировать работу сервера и resolver, то в этом случае имеет смысл включить режим отладки - debug:
> set debug > 1.192.206.144.in-addr.arpa. Server: ns.kiae.su Address: 144.206.130.3 ------------ Got answer: HEADER: opcode = QUERY, id = 20, rcode = NOERROR header flags: response, auth. answer, want recursion, recursion avail. questions = 1, answers = 1, authority records = 0, additional = 0 QUESTIONS: 1.192.206.144.in-addr.arpa, type = ANY, class = IN ANSWERS: -> 1.192.206.144.in-addr.arpa name = quest.polyn.kiae.su ttl = 3600 (1 hour) ------------ 1.192.206.144.in-addr.arpa name = quest.polyn.kiae.su ttl = 3600 (1 hour) >
В данном случае запрашивается имя по "обратному" запросу. Программа транслирует сам запрос и способ его исполнения. Для более сложных запросов трасса может составлять несколько экранов.
Простой сервер
обеспечивает доступ к документам Website и обмен данными с прикладными программами по запросу программы клиента.
Протокол FTP
FTP (File Transfer Protocol или "Протокол Передачи Файлов") - один из старейших протоколов в Internet и входит в его стандарты. Обмен данными в FTP проходит по TCP-каналу. Построен обмен по технологии "клиент-сервер". На рисунке 3.22 изображена модель протокола.
В FTP соединение инициируется интерпретатором протокола пользователя. Управление обменом осуществляется по каналу управления в стандарте протокола TELNET. Команды FTP генерируются интерпретатором протокола пользователя и передаются на сервер. Ответы сервера отправляются пользователю также по каналу управления. В общем случае пользователь имеет возможность установить контакт с интерпретатором протокола сервера и отличными от интерпретатора пользователя средствами.
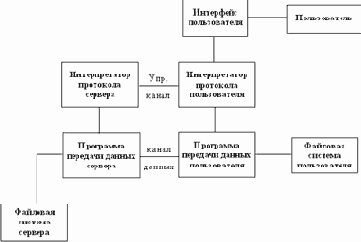
Рис. 3.22. Диаграмма протокола FTP
Команды FTP определяют параметры канала передачи данных и самого процесса передачи. Они также определяют и характер работы с удаленной и локальной файловыми системами.
Сессия управления инициализирует канал передачи данных. При организации канала передачи данных последовательность действий другая, отличная от организации канала управления. В этом случае сервер инициирует обмен данными в соответствии с согласованными в сессии управления параметрами.
Канал данных устанавливается для того же host'а, что и канал управления, через который ведется настройка канала данных. Канал данных может быть использован как для приема, так и для передачи данных.
Возможна ситуация, когда данные могут передаваться на третью машину. В этом случае пользователь организует канал управления с двумя серверами и организует прямой канал данных между ними. Команды управления идут через пользователя, а данные напрямую между серверами (рисунок 3.23).
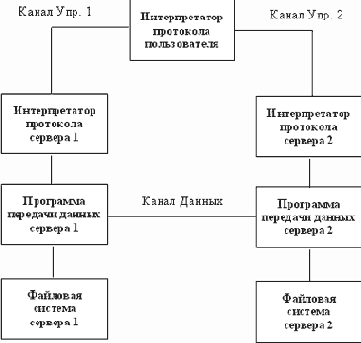
Рис. 3.23. Соединение с двумя разными серверами и передача данных между ними
Канал управления должен быть открыт при передаче данных между машинами. В случае его закрытия передача данных прекращается.
Протокол обмена гипертекстовой информацией (HyperText Transfer Protocol, HTTP 1.0.)
HTTP - это протокол прикладного уровня, разработанный для обмена гипертекстовой информацией в сети Internet. Протокол используется одной из популярнейших систем Сети - Word Wide Web - с 1990 года.
Реальная информационная система требует гораздо большего количества функций, чем просто поиск. HTTP позволяет реализовать в рамках обмена данными набор методов доступа, базирующихся на спецификации универсального идентификатора ресурсов (Universal Resource Identifier), применяемого в форме универсального локатора ресурсов (Universe Resource Locator) или универсального имени ресурса (Universal Resource Name). Сообщения по сети при использовании протокола HTTP передаются в формате, схожим с форматом почтового сообщения Internet (RFC-822) или с форматом сообщений MIME (Multiperposal Internet Mail Exchange). HTTP используется для взаимодействия программ-клиентов с программами-шлюзами, разрешающими доступ к ресурсам электронной почты Internet (SMTP), спискам новостей (NNTP), файловым архивам (FTP), системам Gopher и WAIS. Протокол разработан для доступа к этим ресурсам посредством промежуточных программ-серверов (proxy), которые позволяют передавать информацию между различными информационными службами без потерь. Протокол реализует принцип "запрос/ответ". Запрашивающая программа - клиент - инициирует взаимодействие с отвечающей программой - сервером, и посылает запрос, включающий в себя метод доступа, адрес URI, версию протокола, похожее по форме на MIME сообщение с модификаторами типа передаваемой информации, информацию клиента, и, возможно, тело сообщения клиента. Сервер отвечает строкой состояния, включающей версию протокола и код возврата, за которой следует сообщение в форме, похожей на MIME. Данное сообщение содержит информацию сервера, метаинформацию и тело сообщения. Понятно, что в принципе, одна и та же программа может выступать и в роли сервера и в роли клиента (так собственно и происходит при использовании proxy-серверов).
При работе в Internet для обслуживания HTTP-запросов используется 80 порт TCP/IP. Практика использования протокола такова, что клиент устанавливает соединение и ждет ответа сервера. После отправки ответа сервер инициирует разрыв соединения. Таким образом, при передаче сложных гипертекстовых страниц соединение может устанавливаться несколько раз. Остановимся более подробно на механизме взаимодействия и форме передаваемой информации.
Протокол SMTP
был разработан для обмена почтовыми сообщениями в сети Internet. SMTP не зависит от транспортной среды и может использоваться для доставки почты в сетях с протоколами, отличными от TCP/IP и Х.25. Достигается это за счет концепции IPCE (Inter-Process Communication Environment). IPCE позволяет взаимодействовать процессам, поддерживающим SMTP, в интерактивном режиме, а не в режиме "STOP-GO".
Протокол Telnet
Telnet как протокол описан в RFC-854 (май, 1983 год). Его авторы J.Postel и J.Reynolds во введении к документу определили назначение telnet так:
"Назначение TELNET-протокола - дать общее описание, насколько это только возможно, двунаправленного, восьмибитового взаимодействия, главной целью которого является обеспечение стандартного метода взаимодействия терминального устройства и терминал-ориентированного процесса. При этом этот протокол может быть использован и для организации взаимодействий "терминал-терминал" (связь) и "процесс-процесс" (распределенные вычисления)."
Telnet строится как протокол приложения над транспортным протоколом TCP. В основу telnet положены три фундаментальные идеи:
концепция сетевого виртуального терминала (Network Virtual Terminal) или NVT; принцип договорных опций (согласование параметров взаимодействия); симметрия связи "терминал-процесс".
При установке telnet-соединения программа, работающая с реальным терминальным устройством, и процесс обслуживания этой программы используют для обмена информацией спецификацию представления правил функционирования терминального устройства или Сетевой Виртуальный Терминал (Network Virtual Terminal). Для краткости будем обозначать эту спецификацию NVT. NVT - это стандартное описание наиболее широко используемых возможностей реальных физических терминальных устройств. NVT позволяет описать и преобразовать в стандартную форму способы отображения и ввода информации. Терминальная программа ("user") и процесс ("server"), работающий с ней, преобразовывают характеристики физических устройств в спецификацию NVT, что позволяет, с одной стороны, унифицировать характеристики физических устройств, а с другой обеспечить принцип совместимости устройств с разными возможностями. Характеристики диалога диктуются устройством с меньшими возможностями.
Если взаимодействие осуществляется по принципу "терминал-терминал" или "процесс-процесс", то "user" - это сторона, инициирующая соединение, а "server" - пассивная сторона.
Принцип договорных опций или команд позволяет согласовать возможности представления информации на терминальных устройствах. NVT - это минимально необходимый набор параметров, который позволяет работать по telnet даже самым допотопным устройствам, реальные современные устройства обладают гораздо большими возможностями представления информации. Принцип договорных команд позволяет использовать эти возможности. Например, NVT является терминалом, который не может использовать функции управления курсором, а реальный терминал, с которого осуществляется работа, умеет это делать. Используя команды договора, терминальная программа предлагает обслуживающему процессу использовать Esc-последовательности для управления выводом информации. Получив такую команду процесс начинает вставлять управляющие последовательности в данные, предназначенные для отображения.
Симметрия взаимодействия по протоколу telnet позволяет в течении одной сессии программе-"user" и программе-"server" меняться местами. Это принципиально отличает взаимодействие в рамках telnet от традиционной схемы "клиент-сервер". Симметрия взаимодействия тесно связана с процессом согласования формы обмена данными между участниками telnet-соединения. Когда речь идет о работе на удаленной машине в режиме терминала, то возможности ввода и отображения информации определяются только конкретным физическим терминалом и договорной процесс сводится к заказу терминальной программой характеристик этого терминала. Гораздо сложнее обстоит дело, когда речь идет об обмене информацией между двумя терминальными программами в режиме "терминал-терминал". В этом случае каждая из сторон может выступать инициатором изменения принципов представления информации и здесь проявляется еще одна особенность протокола telnet. Протокол не использует принцип "запрос-подтверждение", а применяет принцип "прямого действия". Это значит, что если терминальная программа хочет расширить возможности представления информации, то она делает это (например, вставляет в информационный поток Esc-последовательности), если в ответ она получает информацию в новом представлении, то это означает, что попытка удалась, в противном случае происходит возврат к стандарту NVT.
Обычно процесс согласования форм представления информации происходит в начальный момент организации telnet-соединения. Каждый из процессов старается установить максимально возможные параметры сеанса. Однако эти параметры могут быть изменены и позже, в процессе взаимодействия (например, после запуска прикладной программы).
В Unix-системах параметры терминалов обычно описаны в базе данных описания терминалов termcap. При инициировании telnet-соединения обычно именно эти параметры используются в процессе согласования формы представления данных. При этом из одной системы в другую обычно передается значение переменной окружения TERM. Если для этого значения переменной TERM имеются одинаковые описания в termcap, то проблем с представлением информации обычно не бывает; если терминал, заказанный в TERM, не определен, то берется стандартный терминал системы. При этом не все функции этого терминала будут задействованы. В процессе договора останутся только те, которые поддерживаются на обоих концах соединения. Часто можно столкнуться с ситуацией, когда значения переменных TERM на локальной и удаленной машинах совпадают, а информация на экране отображается не так, как этого бы хотелось. Скорее всего это вызвано различиями в описании данного устройства в базе данных termcap.
Сетевой виртуальный терминал (NVT). Концепция сетевого виртуального терминала позволяет обеспечить доступ к ресурсам удаленной машины с любого терминального устройства. Под терминальным устройством понимают любую комбинацию физических устройств, позволяющих вводить и отображать информацию. Для тех кто знаком с универсальными машинами серии EC, такое определение терминала не является новым: в момент загрузки системы можно было назначить составную консоль, в которую могли входить устройство ввода с перфокарт и алфавитно-цифровое печатающее устройство (АЦПУ). В более ранних вычислительных комплексах такими терминалами могли быть системная печать и устройство чтения перфоленты (как на МИНСК-22) или телетайп (как на М-6000). Понятно, что за таким понятием терминала стоит требование устойчивости системы, которое было основополагающим для проекта ARPA.
В протоколе TELNET NVT определен как "двунаправленное символьное устройство, состоящее из принтера и клавиатуры". Принтер предназначен для отображения приходящей по сети информации, а клавиатура - для ввода данных, передаваемых по сети и, если включен режим "echo", вывода их на принтер. По умолчанию предполагается, что для обмена информацией используется 7-битовый US ASCII, каждый символ которого закодирован в 8-битовое поле. Любое преобразование символов является расширением стандарта NVT.
NVT предполагается буферизованным устройством. Это означает, что данные, вводимые с клавиатуры, не посылаются сразу по сети, а собираются в пакеты, которые отправляются либо по мере заполнения буфера, либо по специальной команде. Такая организация NVT призвана с одной стороны минимизировать сетевой трафик, а с другой обеспечить совместимость с реальными буферизованными терминалами. Например, таковым и являются терминалы ЕС-7920, из-за которых можно было потерять целый экран информации в случае зависания машины.
В моменты окончания печати на принтере NVT или отсутствия символов в буфере клавиатуры по сети должна посылаться специальная команда GA (Go Ahead). Смысл этой команды заключается в следующем: в реальных компьютерах линия "терминал-процесс" находится под управлением либо терминальной программы (ввод данных), либо печатающей программы. После выполнения своей функции каждая из них возвращает управление и освобождает линию. Обычно это происходит при работе с полудуплексными устройствами, такими как IBM-2741. Для того, чтобы протокол позволял работать и с этими устройствами, введен сигнал GA.
Остановимся более подробно на понятиях принтера и клавиатуры в концепции NVT.
Принтер имеет неограниченные ширину и длину страницы и может отображать все символы US ASCII (коды с 32 - 127), расширенный набор символов (коды с 128 - 255), а также распознает управляющие коды (с 0 - 31 и 127). Некоторые из них имеют специальные значения (таблица 3.1).
Таблица 3.1, Обязательные коды
| Название кода | Код | Значение |
| NULL | 0 | Нет операции |
| Перевод строки Line Feed (LF) | 10 | Переход на другую строку c сохранением текущей позиции в строке |
| Возврат каретки Carrige Return (CR) | 13 | Устанавливает в качестве текущей первую позицию текущей строки |
Рекомендованные коды
| Название кода | Код | Значение |
| Звонок (BEL) | 7 | Звуковой сигнал |
| Сдвиг на одну позицию назад (BACK SPACE) | 8 | Перемещает каретку на одну позицию назад в текущей строке |
| Горизонтальная табуляция Horizontal Tab (HT) | 9 | Перемещение к следующей позиции горизонтальной табуляции |
| Вертикальная табуляция Vertical Tab (VT) | 11 | Перемещение курсора к следующей позиции вертикальной табуляции |
| Прогон страницы Form Feed (FF) | 12 | Переход к новой странице |
Queries
- запросы пользователя сохраняются в его личной базе данных. На отладку каждого запроса уходит достаточно много времени, и поэтому чрезвычайно важно хранить запросы, на которые система дает хорошие ответы.
